
Storage Types
An enterprise MAM system needs different types of storages for proper operation. The most obvious is the storage where the assets (video file, audio files, images, etc.) are stored. In particular for video files, specially designed storages with high throughput and capacities are used.
Other storage usages in an enterprise MAM system are:
-
relational databases
-
search indices
-
configuration data
-
temporary storage
-
log files
-
metrics
-
exports or archives of historical data from relational databases or search indices
These different storages usages not only have different requirements on performance and reliability, they also differ in another important aspect:
-
Several instances of a product component need access to the same storage to get a consistent view on the same data. This usually is implementing by using a shared or central storage which can be accessed by all instances in parallel.
-
Several instances of a product component need their own, dedicated storage; they keep their local copy of the data and syncing between the instances is done over the network. This usually is implemented by using node-local storage where the storage can only be accessed by a specific instance of the product component.
Kubernetes Storage Concepts
Overview
To make different storage types accessible by the Docker containers running in the Kubernetes cluster inside Pods, the Kubernetes concepts of Persistent Volumes (PV), Persistent Volume Claims (PVC), and Storage Classes (SC) are used.
Persistent Volumes are Kubernetes objects which describe a physical storage. This can be a shared storage or a node-local storage.
Persistent Volume Claims are Kubernetes objects which describe the requirements a pod has on the storage it needs.
Persistent Volume Claims can directly refer to a specific Persistent Volume. However, this requires the name of a PV to be known when the PVC is created. To allow the PVC definitions to be more generic, the concept of Storage Classes is helpful.
Storage Classes are Kubernetes objects which define abstract requirements on a storage. The PVC tells Kubernetes which Storage Class it requires and Kubernetes looks for an available PV with the same Storage Class that fits the PVCs demands and connects them. This process is called binding.
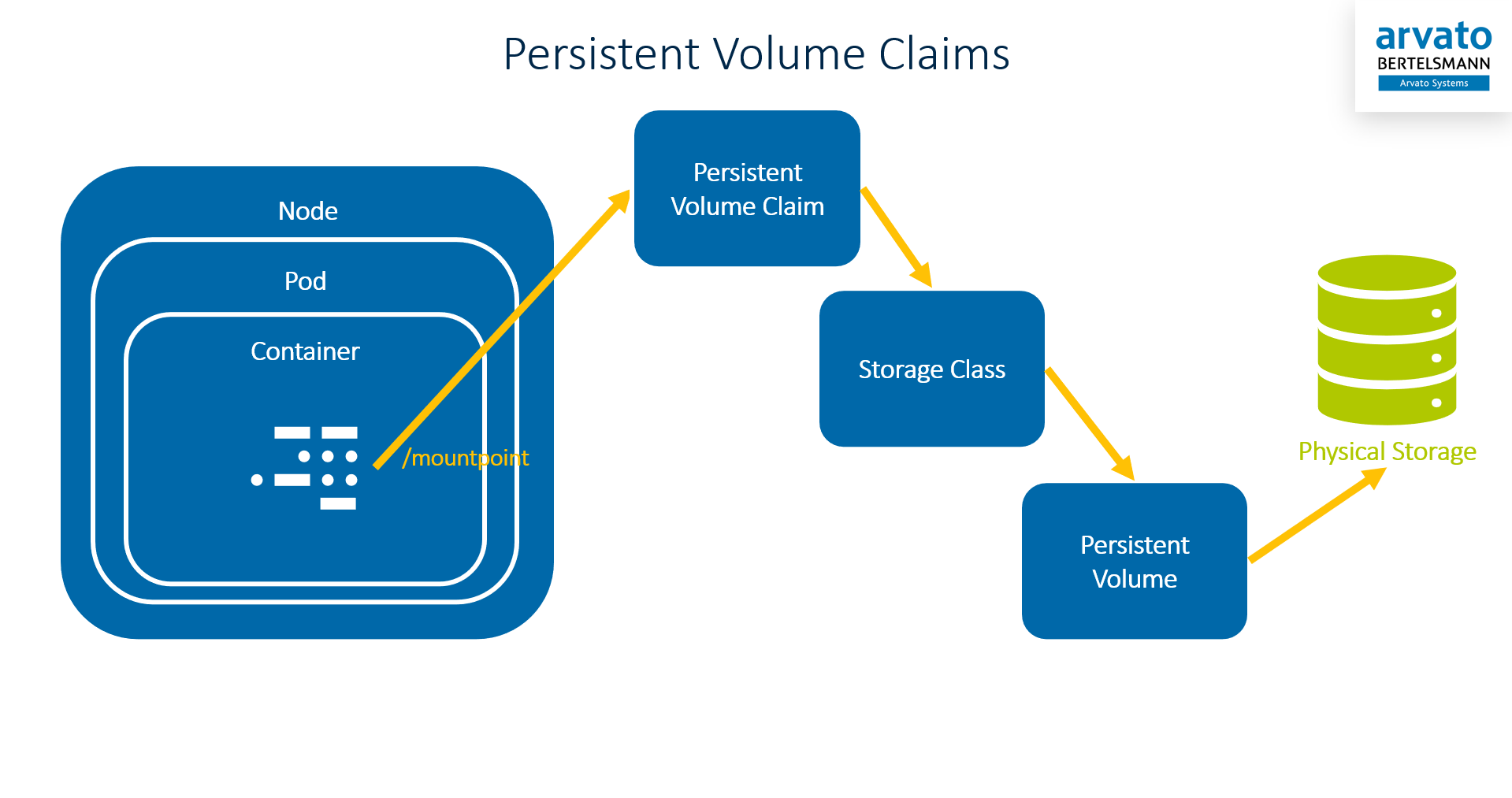
Persistent Volume Claims and Storage Classes are defined by each VidiCore (VPMS3) product and are applied to the cluster during deployment. They are not designed to change during runtime or to differ between different installations of the same product.
Volume Provisioning
Persistent Volumes are the part of the triplet PVC-SC-PV which needs to be created and configured for the the specific environment. All PVs need to be provisioned and provisioning can be a manual process or assisted by Dynamic Volume Provisioners.
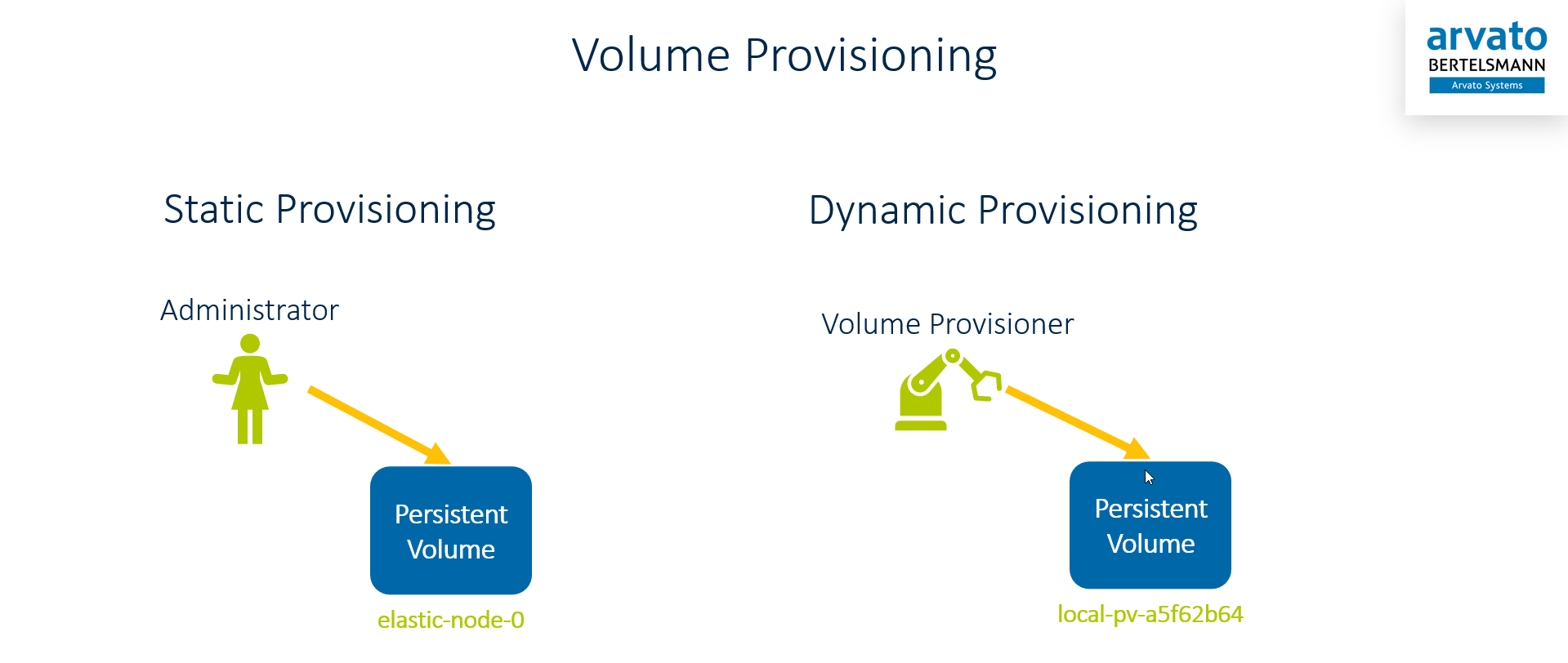
Static Provisioning
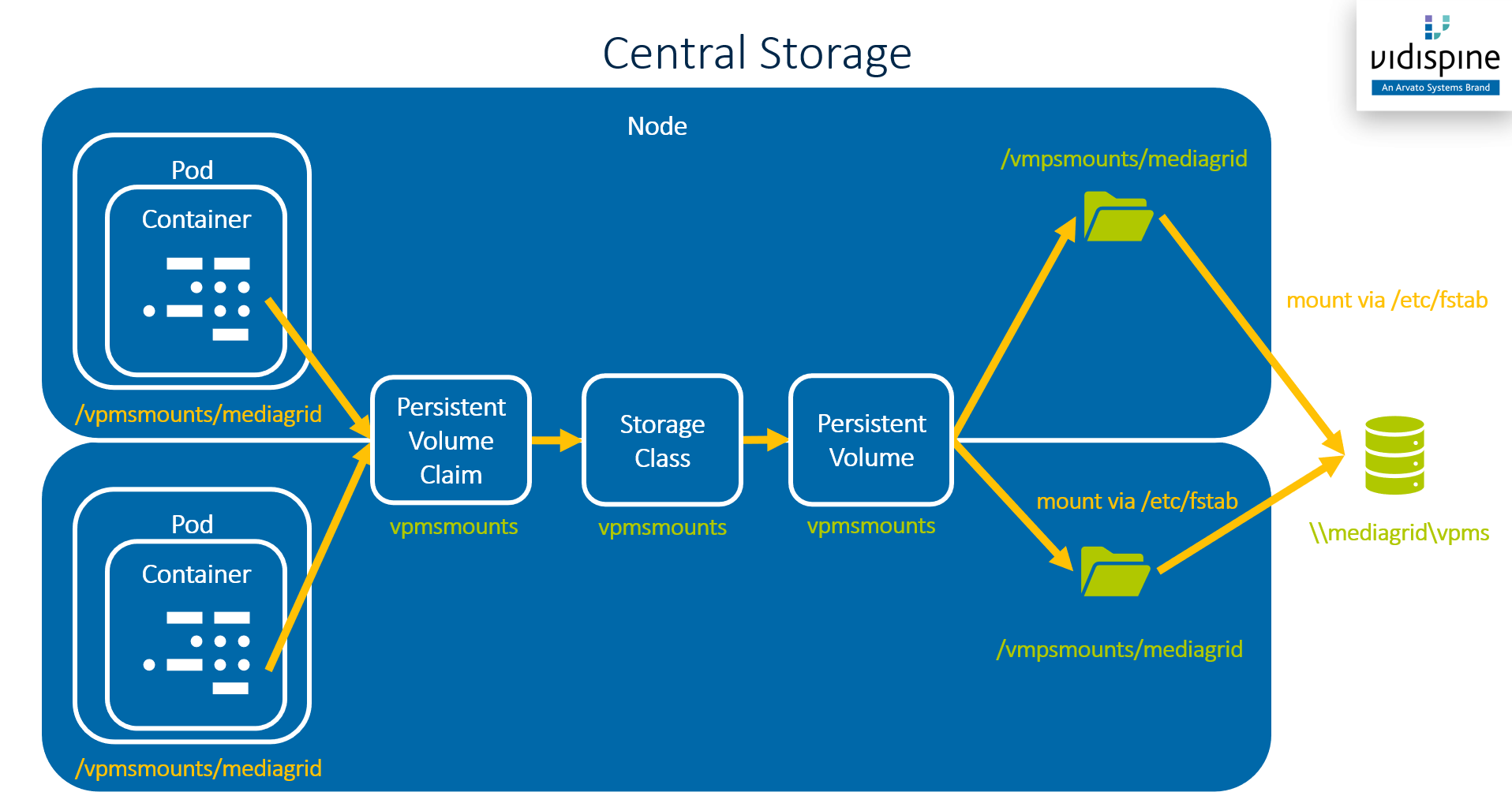
Static provisioning is used in ConfigPortal and VidiFlow for some of the storage usages mentioned above: asset storage, configuration data, and exports or archives of historical data from relational databases or search indices.
For these purposes VidiFlow and ConfigPortal expect the shared storages to be mounted underneath the /vpmsmounts directory on all Kubernetes cluster nodes where pods accessing these storages are allowed to run. It is crucial that the same shared storage location is mounted to the same local directory on all applicable cluster nodes.
|
Purpose |
Storage Type |
Storage Class |
Persistent Volume |
Physical Path on Node |
R/W Access for UID |
|---|---|---|---|---|---|
|
ConfigPortal GIT repo |
Shared |
|
|
|
1002 |
|
Asset storage |
Shared |
|
|
|
1001 |
|
VidiCore and VSA logs |
Node-local |
|
|
|
1001 |
Although ConfigPortal GIT repo and asset storage use the same local path they use different persistent volumes and they can be installed independently and thus should not share Kubernetes objects.
The PVs and PVCs described above are configured to be usable from multiple pods at the same time by setting their Kubernetes Access Modes to ReadWriteMany.
The follow diagram shows the asset storage is mounted into pods which require access to it (e.g. VidiCore or VSA). The network location \\mediagrid\vpms is just an example - any network location which can be mounted to the Linux file system of the cluster nodes can be used.
Dynamic Provisioning
For all other storage types dynamic provisioning is used. With dynamic provisioning the PVs a created dynamically by a Volume Provisioner. Kubernetes comes with quite a lot of dynamic volume provisioners:
-
AWSElasticBlockStore
-
AzureDisk
-
AzureFile
-
CephFS
-
Cinder
-
FC
-
FlexVolume
-
Flocker
-
GCEPersistentDisk
-
Glusterfs
-
iSCSI
-
Quobyte
-
NFS
-
RBD
-
VsphereVolume
-
PortworxVolume
-
ScaleIO
-
StorageOS
-
Local
The three big cloud providers are supported and can (and should) be used when deploying VidiFlow on a managed Kubernetes cluster on the Azure, Amazon, or Google cloud. For vSphere-based systems the VsphereVolume provider is a good option - although untested in VidiFlow up to now.
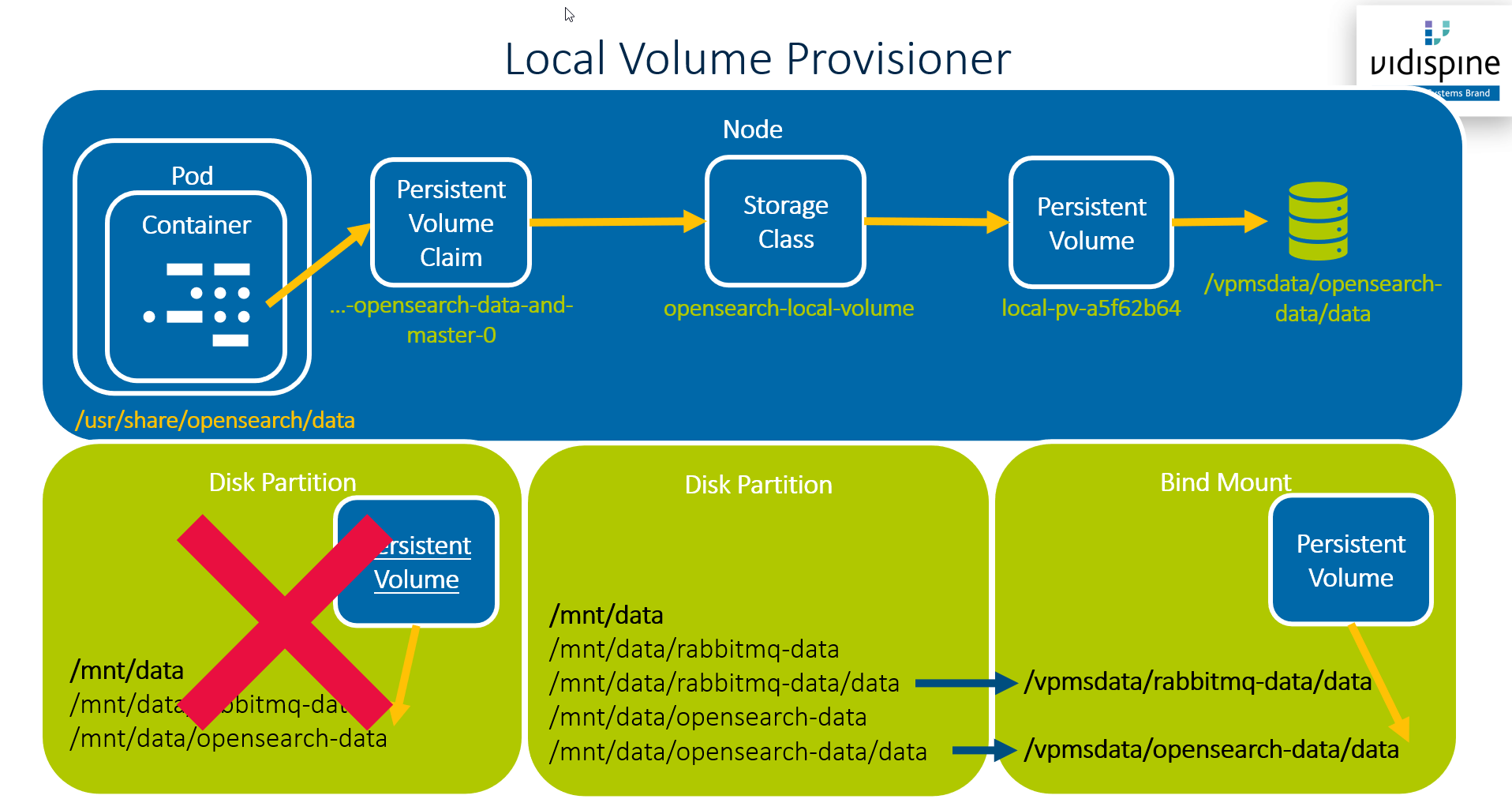
The local dynamic volume provisioner is used in VidiFlow for all node-local storage:
-
OpenSearch indices
-
RabbitMQ storage
-
Prometheus metrics storage
-
Alertmanager storage
The following diagram shows how this works:
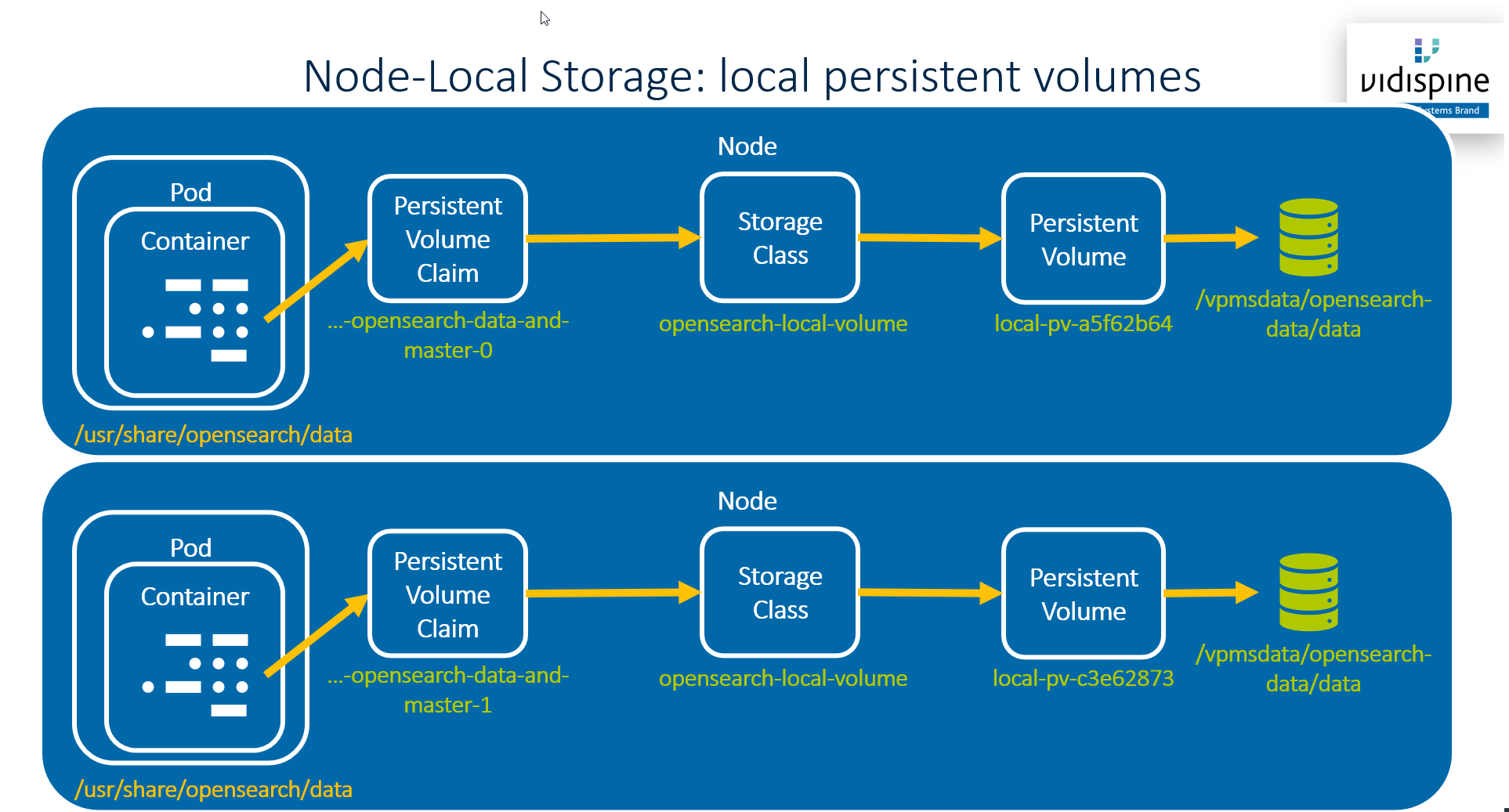
A small downside of this solution is that you cannot use any file system location for /vpmsdata/opensearch-data/data - the Kubernetes local volume provisioner requires it to be a mount point. To avoid creating to many small partitions the default VidiFlow deployment uses bind mounts to create multiple mount points from a single locally-attached disc.
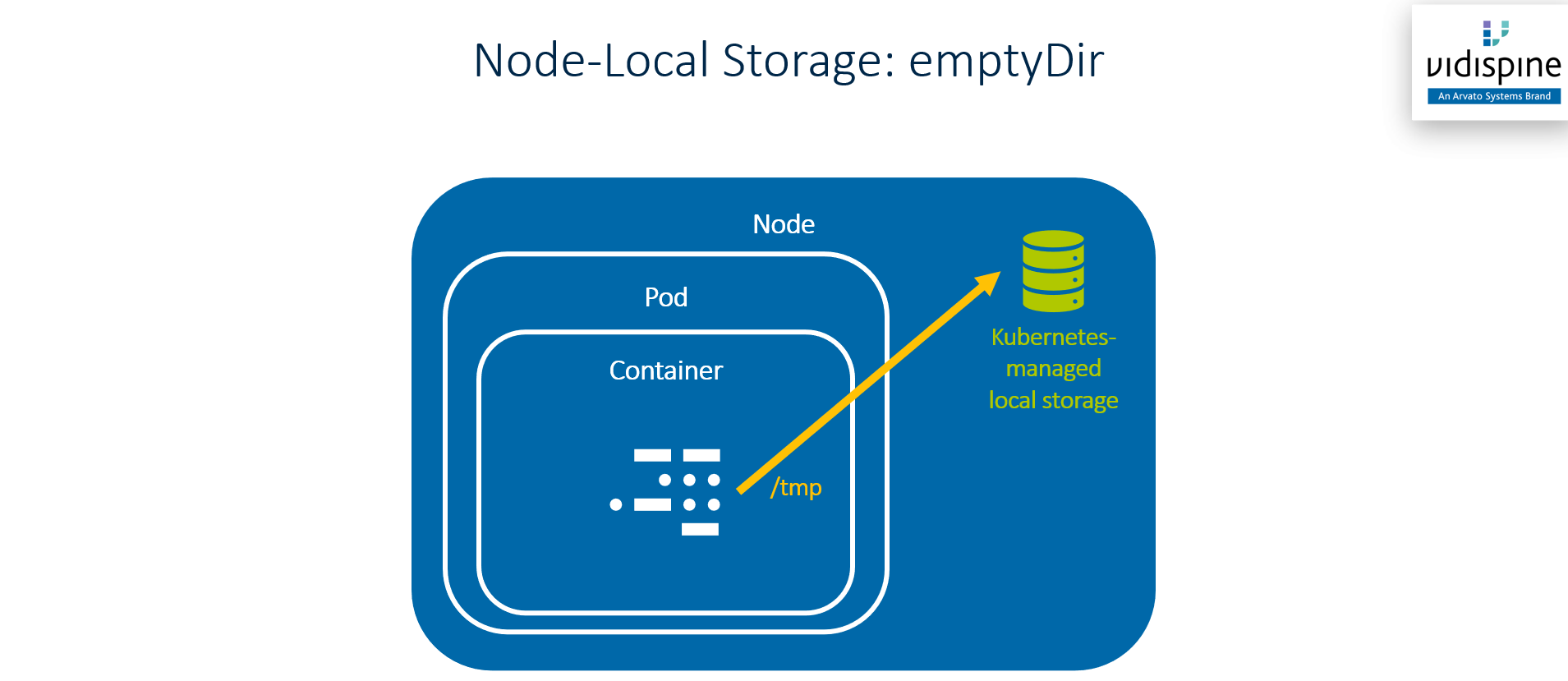
Temporary Storage
Temporary storage (e.g. the Linux /tmp folder) can be attached to pod in a much simpler way by using emptyDir volumes. An emptyDir volume is fully managed by Kubernetes. Kubernetes uses disc space on the cluster node where the pod is running on and provides this to the pod. emptyDir volumes are ephemeral, i.e. their contents is deleted when the pod is deleted.
For Further Reading
-
A good overview on Kubernetes Persistent Volumes: https://phoenixnap.com/kb/kubernetes-persistent-volumes
-
The official Kubernetes docs: https://kubernetes.io/docs/concepts/storage/persistent-volumes/