Load Balancing and MetalLB
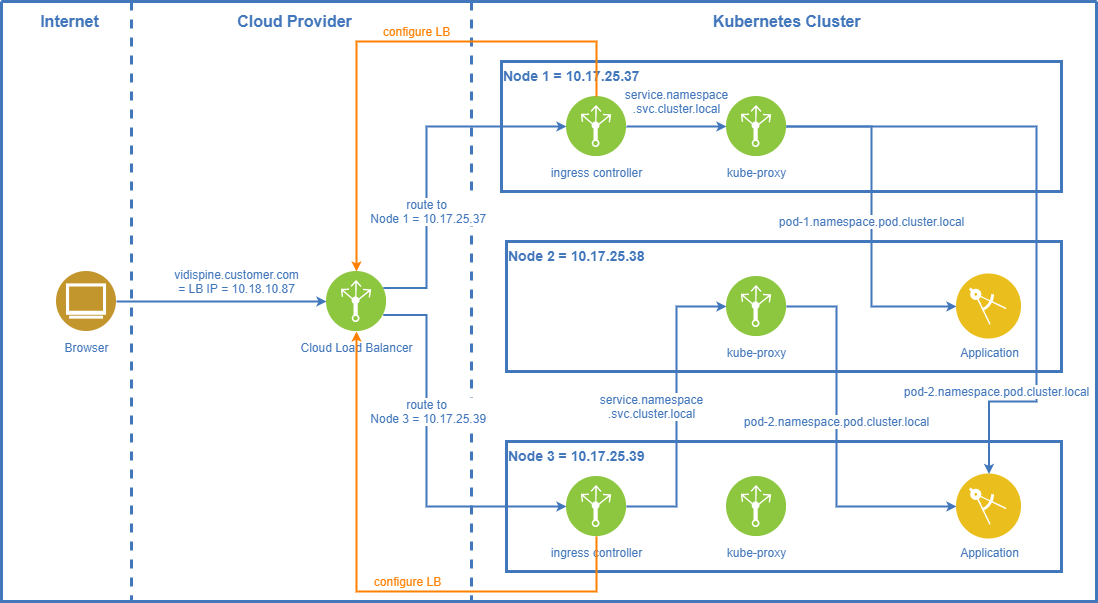
Cloud
When using managed Kubernetes clusters in the cloud (Azure, AWS, Google) the Kubernetes ingress controller(s) can create and/or communicate with the load balancer(s) of the respective cloud provider. This connection between the ingress controller and the cloud load balancer ensures that the cloud load balancer routes the traffic to the cluster nodes where the ingress controllers are running on. It also ensures distribution of the traffic between these cluster nodes according to the rules available on the cloud’s load balancers.
On-Premises
For on-premises systems there’s no ready-made concept available in Kubernetes. This is where MetalLB jumps in.
MetalLB can run in two different modes:
Layer-2 mode
BGP mode
MetalLB Layer 2 Mode
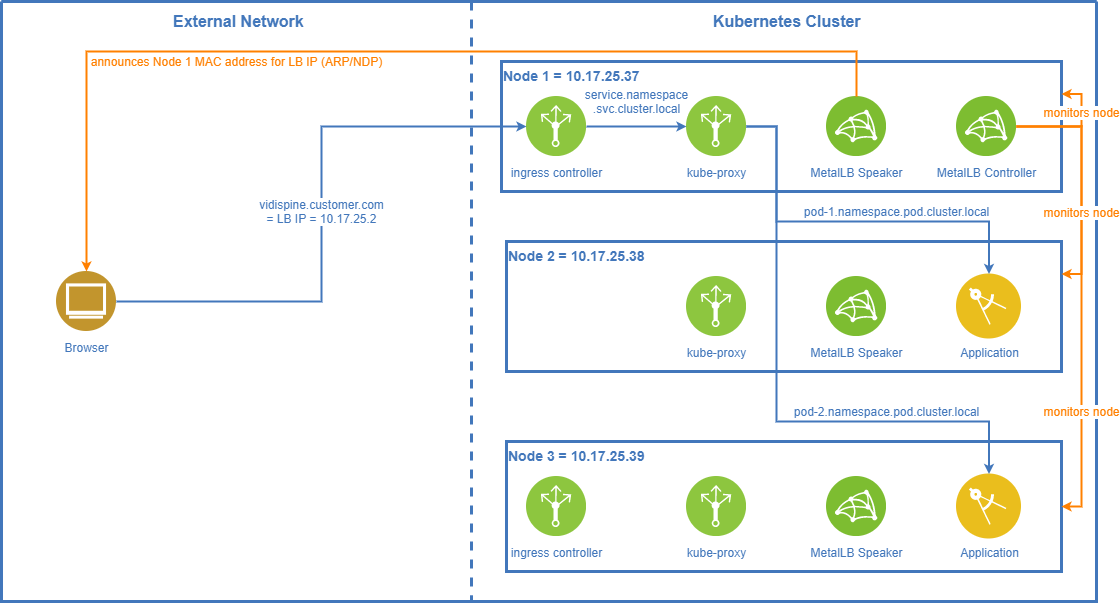
How It Works
In layer-2 mode a virtual load balancer IP needs to be defined. The hostname of your application (https://vidispine.customer.com in the diagram) needs to resolve to this virtual IP.
The MetalLB controller running in a single instance decides which node should receive the traffic for the virtual IP. The MetalLB speaker on the designated node responds to ARP/NDP requests for this LB virtual IP and returns the MAC address of the node it is running on.
When the MetalLB controller detects that the designated node is down, it selects one of the other nodes for receiving the external traffic. Now the MetalLB speaker on the new node takes over and will respond to ARP/NDP requests for the LB virtual IP.
In case the node with MetalLB controller does down Kubernetes will start up the controller pod on a different node.
ExternalTrafficPolicy
In Kubernetes there are two ways how services of type NodePortor LoadBalancer can route traffic and the service property ExternalTrafficPolicy determines the behavior. This is either the local policy or the clusterpolicy. When traffic hits a cluster node, the local policy will only forward traffic to pods running on the same node. If the policy is set to cluster the Kubernetes internal loadbalancing kicks in and the traffic will be forwarded to a randomly selected pod fronting the service, this means any node can be accessed and internal routing makes sure that it is delivered. For a detailed overview of diffferences see https://www.asykim.com/blog/deep-dive-into-kubernetes-external-traffic-policies.
When using the HaProxyIngress Controller, note that the default setting for the ingress controllers LoadBalancer type service is local (which is not the Kubernetes service default of cluster). In essence this local setting means in combination with Layer2 mode that the MetalLB controller pod (which is responsible for controlling the cluster access) must make a node the designated node where a HaProxyIngress controller pod is running on. Only in this case the arriving traffic is locally forwardable to a pod running on the node.
In order to have local policy working with MetalLB Layer2 mode it is required that:
the node where the HaProxyIngress controller pods run on is on the same subnet as the virtual IP that is to be used for ingress. Since the node announces the VirtualIP to route to the nodes MAC address it must be in the same subnet as the virtual IP announced.
a MetalLB speaker pod is running on the node where the HaProxyIngress controller pods run. By default the speaker pods run as a DaemonSet and are available on all nodes, however it would be possible to limit the allowed nodes via affinities or tolerations.
If changing the setting to cluster policy the assumption is that any node whereupon a speaker pod is running can become the designated node. It does not matter at which node traffic arrives since it is being internally loadbalanced to the pods serving the LoadBalancer type service.
For performance reasons it is highly likely that the local policy is the better option because additional hops due to internal K8S load balancing are left out. Especially with the Layer2 mode configuration of MetalLB this should be the most performant mode of running MetalLB and an ingress controller on-premise. This however needs proper verification.
Drawbacks
Failover from one node to another may take up to 10 seconds. During this time the system is not reachable.
As the LB virtual IP always points to a single node there is no load balancing taking place. Only failover in case of a node failure is ensured.
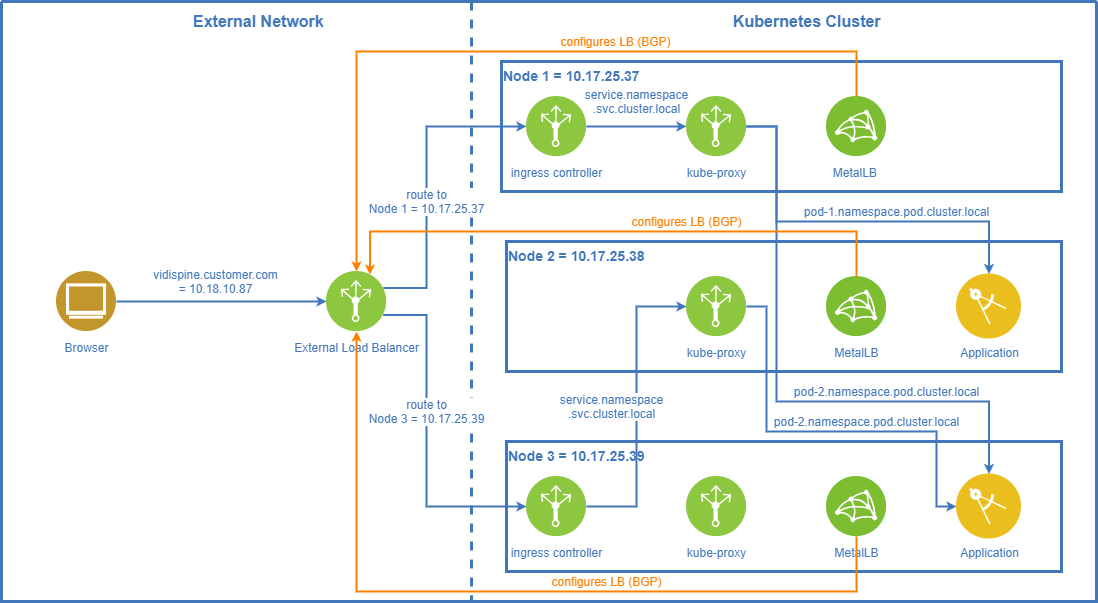
MetalLB BGP Mode
How It Works
In BGP mode MetalLB configures the external load balancer via the Border Gateway Protocol (BGP) to route the traffic to one of the cluster nodes.
Please note that BGP support still is experimental in Vidispine on-prem/hybrid/BYOC MAM. Projects may face issues when activating MetalLB’s BGP mode.
Drawbacks