
Introduction
With start of 24.2 PREPARED starts to address security critical issues predominantly.
Main topics herein are:
-
fix lifecycle of main container service accounts
-
integration of external secret provider such as AWS key vault
-
improve credential handling for Vidicore administrative credentials
Another important aspect is the update of product helm charts that have been outdated. The following Helm charts have been redesigned to support latest deployment configuration features:
-
AuthService
-
ConfigPortal
-
VidiStream
-
VidiEditor
Other focus points are:
-
improve storage handling in PREPARED
-
implement global CORS configuration concept
Migrations
ServiceAccount (SA) Migrations
Background
Kubernetes creates a ServiceAccount named default in every namespace that is created. This is an automatism to provide a fallback ServiceAccount that each pod in the namespace will use if no explicit ServiceAccount is configured. However, if particular RBAC rights are to be assigned to the pod via it’s ServiceAccount, more granularity and thus more ServiceAccounts are needed.
Within the HULL Helm chart library, which is a building block of many Vidispine Helm charts, a single ServiceAccount named <RELEASE-CHART-PREFIX>-default is created by default as well. This ServiceAccount is configured for all pods that are created within the Helm chart by default as well. In case RBAC rights are to be assigned, this per-release ServiceAccount provides more flexibility, especially considering that it is recommended to use individual ServiceAccounts per pod.
However, the <RELEASE-CHART-PREFIX>-default SA’s that were created prior to Release 24.2 have a flaw: they are marked as Helm Hooks. Helm Hooks are a mechanism to control execution order during an installation of a Helm release, they can be utilized to run Jobs for e.g. database creation or API registrations before the actual application pod is started (pre-install). Or they can run after the main Chart components have been installed to interact with the now running application(post-install). When sharing a single SA for all needs in a Helm chart they were (without much afterthought) tagged as Helm Hooks to create them before even the first pod is created in the pre-install phase.
Therefore this was done originally to adapt the single ServiceAccount per Helm chart to different timings, But there is a significant price to pay when relying on Helm Hooks: they are not managed as part of the Helm Release but have a different (configurable) lifecycle which can cause problems if long-running pods interact with the Kubernetes API and the lifetime of the ServiceAccount tokens does not match the pods lifetime,
To rectify the situation and problems, the following steps were undertaken:
-
for all HULL based charts, remove the Helm Hook annotations from the
<RELEASE-CHART-PREFIX>-defaultSA so it’s lifecycle reflects the lifecycle of the Helm releases main pods -
create dedicated SA’s for other dedicated purposes, these are usually:
-
default
-
database create and reset jobs
pre-install -
hull-installjobs to create preconditions for installation of application -
hull-configurejobs that interact with the installed application after setup
-
In short, it is required to remove the Helm Hook annotations from the <RELEASE-CHART-PREFIX>-default SA’s . When the respective annotations are removed, the SA objects need to be “adopted” by the respective Helm Chart releases. This is done by adding the following annotations to the objects marking them as managed by Helm:
-
meta.helm.sh/release-name=<RELEASE> -
meta.helm.sh/release-namespace=<RELEASE-NAMESPACE>
and the label:
-
app.kubernetes.io/managed-by=Helm
Additionally, removing the Helm Hook annotations is required:
-
helm.sh/hook-delete-policy -
helm.sh/hook-weight -
helm.sh/hook
If the above steps are done on any Kubernetes object which was a Helm Hook it will be considered belonging to a particular Helm release <RELEASE> afterwards. This means that the re-labeling and re-annotating needs to be done for each HULL based release in your cluster. Only if successfully executed the subsequent helm install will not fail due to the presence of the object which now is supposed to be part of the release.
With PREPARED release 24.2 the migration steps are automated. For each Helm release to migrate, a predecessor step named <RELEASE>-sa-migration is executed prior to the release update. Within <RELEASE>-sa-migration the relevant objects are annotated and labeled according to the description above so that the subsequent <RELEASE>-sa-migration helm install --update operation should be successful.
Implementation
PREPARED offers a mechanism that takes care of the required steps for the SA migration. Using the layer feature all additional steps are wrapped together in a PREPARED layer that must be included in your projects layers.yaml. This migration layer is simply included like this:
---
layers:
...
migrations:
origin: "oci://{{ hostvars['deployer']['docker_registry_user'] }}:{{ hostvars['deployer']['docker_registry_password'] }}@{{ hostvars['deployer']['host'] }}/prepared/layers/migrations:24.2.5"
The migration layer contains a large number of Helm release definitions for the discussed <RELEASE>-sa-migration releases. Each <RELEASE>-sa-migration release is built on the cluster-admin HULL chart which provides administrator level rights to a pod running kubectl commands. The commands which are run in each pod are provided above.
Some migration steps involve additional kubectl steps which are explained in the relevant section of this guide
Due to the usage of the install_before PREPARED feature in the migration layer steps it is allowed to run a complete PREPARED tag such as env, obs or vf and the correct order of steps is guaranteed. It is not required to individually execute <RELEASE>-sa-migration steps before the <RELEASE> step, running a full tag is sufficient.
For Flux based systems, the corresponding depends_on settings are made so that in a Flux managed system the migration steps are also executed before the corresponding <RELEASE>-sa-migration steps.
It is strongly advised to delete all <RELEASE>-sa-migration Helm releases from the clusters and remove the migration layer for 24.2 after a succesful migration!
Due to the elevated rights of the pods running kubectl they may pose a unnecessary security risk which can easily be eliminated.
Known Issues
Depending on the state of the system prior to the migration and the specific steps some problems may arise during this migration that may require manual intervention for getting them resolved:
StatefulSets
StatefulSets are not as easy upgradable as Deployments.
-
Some changes require a downscale to zero of all pods and a following scale up so that pods are started with a new configuration
-
Some changes may be not allowed and require a manual removal of the StatefulSet in order to be performable.
As long as the corresponding PersistentVolumeClaims are not being deleted this is normally an acceptable measure but when in doubt please ask for assistance from the DevOps team
Turning regular Helm managed objects into Helm Hooks (especially pre-install Hooks)
This bug ticket describes a rather unexpected side effect of turning an Helm managed object into a Helm Hook from one installed release to the next. With the added Helm Hook annotations, the objects are not managed by the Helm release anymore, they are even actively being deleted if encounted in the cluster. Details in the linked issue.
Storage Setup changes
VidiCore Credential Handling
Background
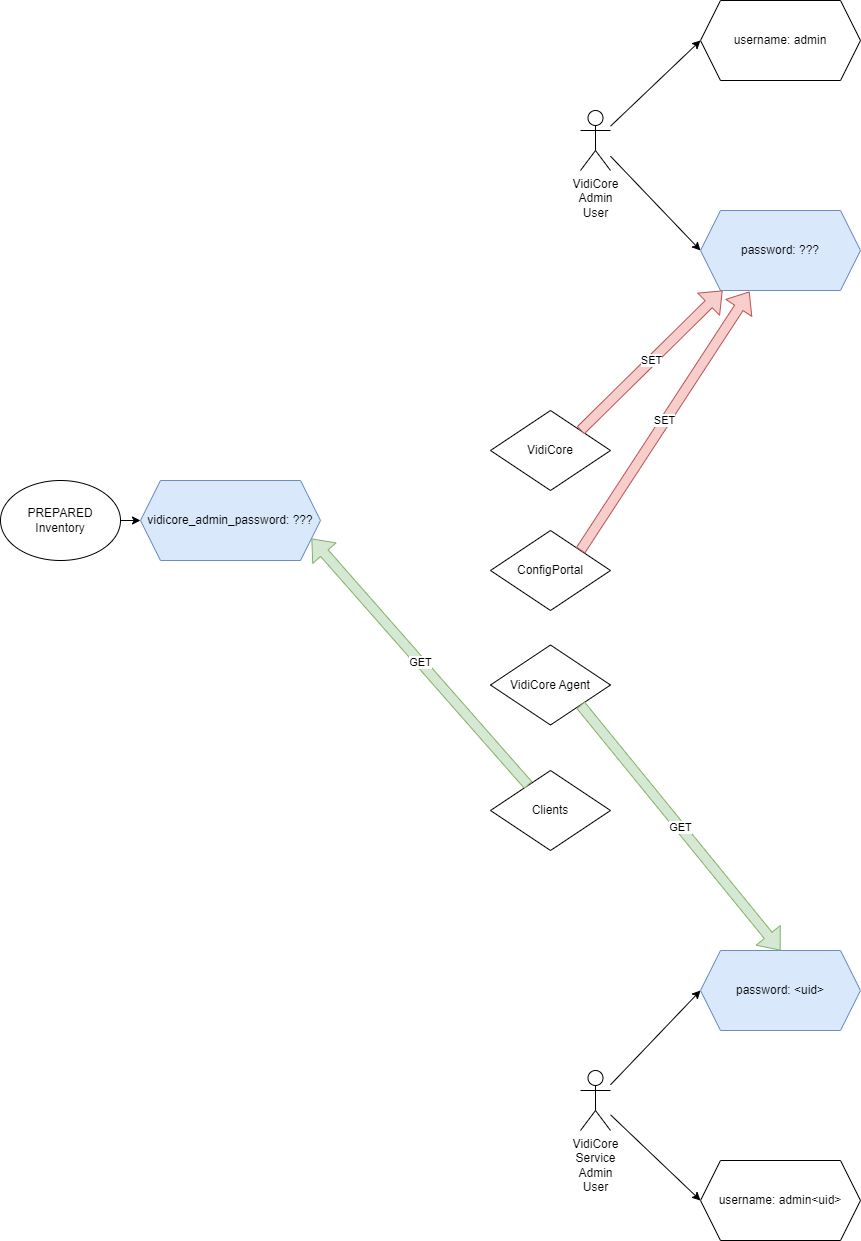
In the context of VidiCore there are different admin users whose lifecycle and purpose wasn’t clearly defined. This is first a description of the users and the old state of their usage in systems:
The Vidicore admin user
This is the user whose password can be changed in ConfigPortal and which should give customers the possibilitity to do administrative work on VidiCore.
While a value named vidicore_admin_password was available in the PREPARED inventory, it was not used to change the admin users password on initial installations, instead it was wrongly used to provide admin credentials to some applications that require them (mainly for registration of notifications in VidiCore).
Since there was never an automated setting of this password and it could be changed anytime in VidiCore. It clearly indicates that this was a misuse of the admin user for this purpose because a manual change in ConfigPortal invalidates backend logins. The service-admin user is the one which should be used by backend applications in the cluster to obtain VidiCore admin rights.
Due to the fact that vidicore_admin_password was never used to actually set the VidiCore admin users password it remained as admin after initial installation unless somebody changed it manually in ConfigPortal or via API. This poses as a security issue making it easy to for attackers to change the password or access the API via admin/admin if it was never changed manually!
The VidiCore service-admin user
This is a service user with admin rights which is created during the installation process of VidiCore. The name and password for this user is autogenerated randomly and it is being created in VidiCore.
The username and password are stored in a secret in the namespace of VidiCore (represented as <system-name>) named typically:
<system-name>-vidispine-admin-user
The secret was created by the VidiCore installation in the <system-name> and kube-system namespaces for backup.
The only application actively using this secret to login to VidiCore was the vidicore-agent.
This diagram sketches the situation prior to release 24.2:
Improvements
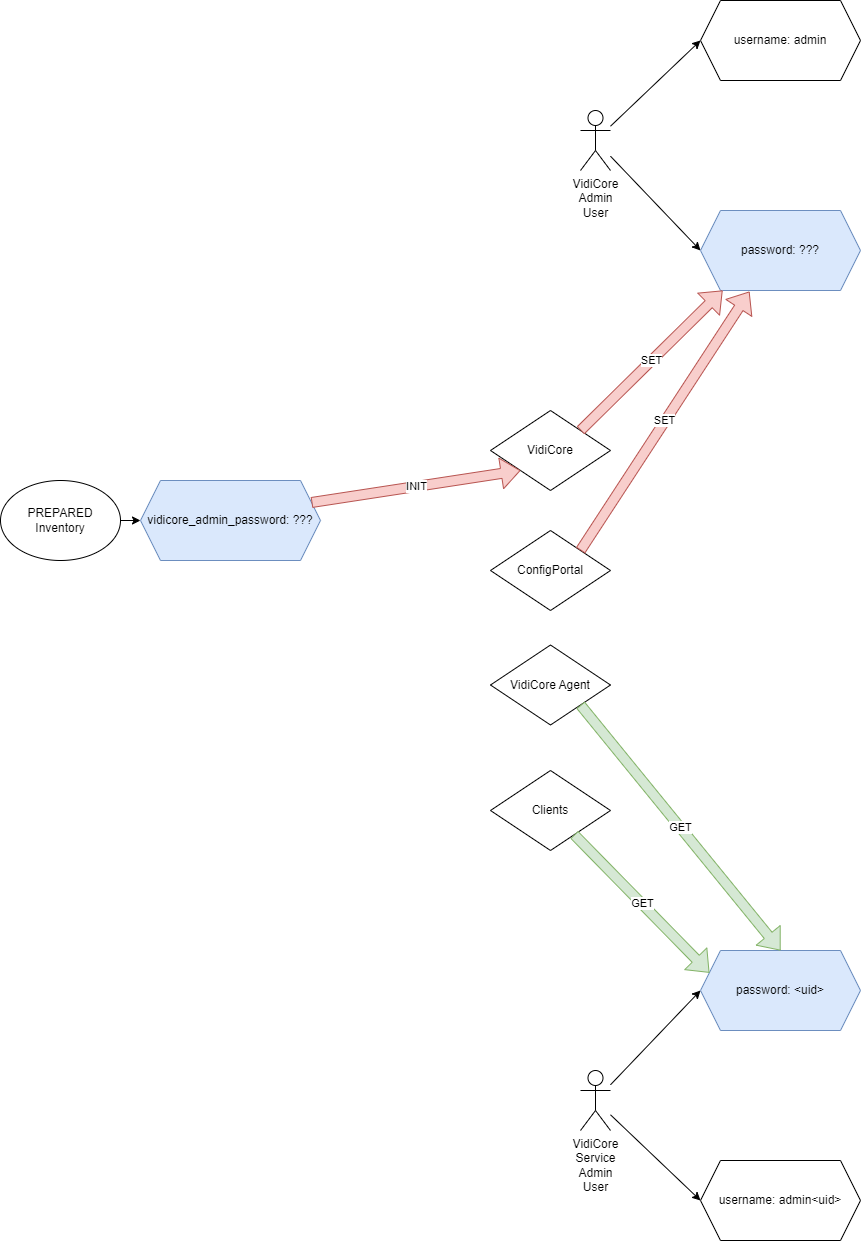
Corrected the lifecycle and usage of admin and service-admin users and credentials.
The vidicore Helm chart has been modified to do the following on each installation or update:
-
the
vidicore_admin_passwordsets theadminusers password initially whenadmin/adminis detected. The passwordadminor empty or whitespace is disallowed by a script check -
check the existence of
<system-name>-vidispine-admin-userand if not existing, create it with the annotations for reflection byreflektorso it is distributed to all relevant namespaces (kube-system, all namespaces starting with<system-name>
The migration layer handles:
-
The
service-adminuser is used for all backend application logins. For this to work, the<system-name>-vidispine-admin-usersecret must be replicated to all relevant namespaces where backend pods are running. Additional migration steps have been added to themigrationlayer that will annotate any existing<system-name>-vidispine-admin-userfor use withreflektor
Product Helm charts have been updated to:
-
read VidiCore admin credentials from local secret
<system-name>-vidispine-admin-userinstead of relying onadmin. This affected:-
mediaportal -
vidieditor -
vidicontrol -
medialogger
-
With these changes the lifecycles are seperated and independent from each other:
Summary
|
Issue |
Old |
New |
Gain |
|---|---|---|---|
|
The |
Value was never used as a setter in any way |
The If at any installation or update time of VidiCore it is detected that the combination |
|
|
The |
The applications relying on |
Applications running in the cluster dynamically look up the |
|
|
Indeterminate accessing of systems using |
|
|
|
|
|
|
|
|
|
|
|
|
|
Security Improvements
A process has started to make it possible to manage sensitive data in an external store (such as AWS Key Store) instead of the PREPARED inventory vault files. The External Secrets Operator application is responsible for syncing the external secret storage with the in-cluster secrets. This task is ongoing and expected to finish with the next release.
The advantages from a security perspective are:
-
Management of sensitive data is removed from the PREPARED tooling, reducing the risk of leaking sensitive data in GIT repositories and log files during deployment.
-
Customers can enforce strict password rules
Redefined Job templates for vidiflow-media-agents
Prior to version 24.2, the Kubernetes Job templates for the mediaframework-transode and mediaframework-command-line Jobs were defined using Kubernetes Job YAML syntax. Whenever a transcode or command-line Job is to be started, the templates are enriched with runtime data and then create Kubernetes Jobs. The major problem with defining these Job templates in native Kubernetes YAML syntax is that it is very difficult to apply specific changes to them pertaining the volumeMounts and volumes sections.
Assume the common scenario that a vpmsmounts storage should be added to the usable volumes. This would require appending to the volumeMounts and volumes arrays on the PREPARED level. Technically, modyfing deeply nested array structures in PREPARED is supported to some degree but in this case it is currently not possible.
To overcome this problem, the Job templates are now to be defined in the style of HULL Jobs. The design of HULL especially considered the problems of array merging and offers dictionaries with better merge support for amongst other fields volumeMounts and volumes. The HULL job definition style also brings with it the full feature set of HULL and thus offers further advantages which the raw Kubernetes YAML approach misse such as:
-
Rich metadata is automatically added to each Job
-
Docker Image registry handling is simplified in HULL
-
…
From the deployment perspective the same result is achieved: while the old Kubernetes YAML template was already being written to a configmap, the new HULL templates are rendered to the same ConfigMap yielding a functionally equivalent Kubernetes Job YAML.
If your inventory contains modifications of the templates shown above, these modifications need to be adjusted to the new HULL structure of the templates.
Please ask for assistence of the DevOps team when you need help on this!
Here is a comparison of the old style template definitions and the new HULL template definitions of the transcode and command-line jobs:
|
Aspect |
Release <= 24.1 |
Release >= 24.2 |
|---|---|---|
|
Template Definition Style |
Kubernetes Job YAML |
HULL Job YAML |
|
In |
|
|
There is also a very recent addition to the vidiflow-vidicore-agents Helm chart which also represents VSA transcode Jobs in the same way as the transcode and command-line jobs in vidiflow-media-agents. The job template structure has also been changed to HULL based Job templates in the same way.
If you already use these Jobs, the same adjustments may need to be done in inventories if the templates are modified on the PREPARED level.
Step-by-Step Overview
|
Role |
Migration Actions |
Manual Actions |
|---|---|---|
|
|
|
|
|
|
None |
|
|
Set required values in inventory and vault respectively:
The |
|
|
None |
|
|
|
None |
|
|
|
Set required values in inventory and vault respectively:
The chosen |
|
|
|
Storage settings may need to be adapted to system settings for a smooth upgrade: Depending on the original setup of the
Please check the current cluster settings for In case of further problems during installation:
|
|
|
|
Changed configuration method for Job templates used in As explained, carefully adjust any modifications to the Job templates to the new HULL based Job template structure.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Set required values in inventory and vault respectively:
|
Known Issues
AuthService Installation
Due to the Helm issue mentioned above and a potential bug in the HULL library it is possible that in update scenarios you cannot upgrade AuthService cleanly and encounter an error like this:
Secret authservice-keycloak-user does not exist
It is recommended in this case to delete the authservice Helm release from your cluster and recreate it during the 24.2 release installation. No data is affected because all relevant data is stored in the database and no local storage is deleted which may lead to data loss.