This article is divided into the following sections:
Introduction
The DeepVA Face Training Theme for VidiCore is an application designed to visualize the capabilities of the DeepVA Face Recognition & Analysis services in VidiNet. The application contains functions for analyzing video content with DeepVA AI services in VidiNet, managing and organizing the face datamodel/database with VidiCore, train the data model with known faces prior to analysis of content, grab faces in videos manually, and much more. The powerful indexing services in VidiCore makes it easy to find and display persons and faces using timecoded metadata in combination with AI.
At its core, the Face Training Theme is a lightweight application with minimal configuration required. The only prerequisite is a live instance of VidiCore with an S3 storage, a connected VidiCoder, and one or more connected DeepVA services.
The DeepVA Services in VidiNet
The “Face Training and Analysis Powered by DeepVA” service will enable the powerful AI capabilities of DeepVA for analyzing video content to find faces both unknown and known to the system. Each finding will be fingerprinted and compared, with duplicates being grouped into one fingerprint. All findings will preserve the timecode where the face was found, in order to properly display search results in the user interface. This service also offers the ability to pre-train a face model before analyzing large amounts of content.
The “Face and Label Extractor Powered by DeepVA”-service will do a thorough frame-by-frame analysis of videos to find faces and match this with any textual information found in the lower third area of the video. Analysis results from this service will NOT preserve the timecode from where the face was found, but the output can be used to pretrain the face data model for usage with the other DeepVA service, i.e. “Face Training and Analysis by DeepVA”. The output of the “Face and Label Extractor powered by DeepVA”-service is, simply put, a set of still images of a persons face alongside a suggested name of the person based on the findings in the lower thirds.
Demonstration video
Here is a short video of how it works:
Prepare your VidiCore System
For this guide, we assume that you have a VidiCore instance running. This can either be running inside VidiNet, or as a standalone local instance, with at least one S3 item storage and one connected VidiCoder service from VidiNet.
Your VidiCore system needs to be version 21.3 or later in order to use DeepVA services.
Before you can start analyzing video content and organize found faces you need to launch and register the “Face Training and Analysis Powered by DeepVA”-service from the store in the VidiNet dashboard. You also need to do some manual configuration in your VidiCore system as well as on your S3 bucket(s). The exact details on how to do this can be found here: Face Training and Analysis Powered by DeepVA Setup and Configuration [VCS 21.4 UG] .
If you also want to use the “Face and Label Extractor powered by DeepVA” service, the setup is very similar and explained here in detail: Face and Label Extractor Powered by DeepVA Setup and Configuration [VCS 21.4 UG] .
Accessing the Application
The Face Training Theme for VidiCore runs as a serverless one-page application. The latest compiled version can be found here: https://vidispine.github.io/face-training-theme/. This version can be run towards any VidiCore system which has been properly configured for use with DeepVA services. See instructions above.
In addition, the following configuration is needed:
Adding CORS Configuration to VidiCore
In order to use the application towards your VidiCore system, the following CORS configuration must be added in VidiCore. This can be done in the console of your choice or via Postman.
PUT /API/configuration/cors
<CORSConfigurationDocument xmlns="http://xml.vidispine.com/schema/vidispine">
<entry>
<request>
<origin>https://vidispine.github.io/face-training-theme</origin>
</request>
<response>
<allowOrigin>https://vidispine.github.io/face-training-theme</allowOrigin>
<allowMethods>OPTIONS,GET,HEAD,POST,PUT,DELETE</allowMethods>
<allowHeaders>accept,content-type,authorization,index,size,runas</allowHeaders>
<allowMaxAge>600</allowMaxAge>
</response>
</entry>
Erroneous or missing CORS configuration will render an error in the application login screen
Add S3 CORS Policy
In order for the application to display thumbnails and allow playback of media, a CORS configuration is needed on the AWS S3 bucket used as media storage in your VidiCore system. This configuration can be applied either via the AWS console or the AWS website.
<CORSConfiguration>
<CORSRule>
<AllowedOrigin>https://vidispine.github.io/face-training-theme</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
</CORSRule>
</CORSConfiguration>
Erroneous or missing S3 CORS configuration will render errors in the user interface
Configuring the Application to Use a VidiCore API Endpoint
Log in to the application using the username and password of a user account in your VidiCore system
Accessing the Source Code
The Face Training Theme for VidiCore application is built using the VidiCore Developer Toolkit, allowing all components to be repurposed to fit your user interface needs. The source code for application can be found on GitHub: https://github.com/vidispine/face-training-theme
Access Denied or no GitHub account?
Create an account here https://github.com/joinand then send your GitHub username to info@vidispine.com with a request to obtain access to the Face Training Theme for VidiCore from the Vidispine Repository.
With access to the repository in GitHub, you will be able to modify and run the application locally. Remember to adjust your CORS settings for the application for it to run correctly.
Using the Application
Upload Videos
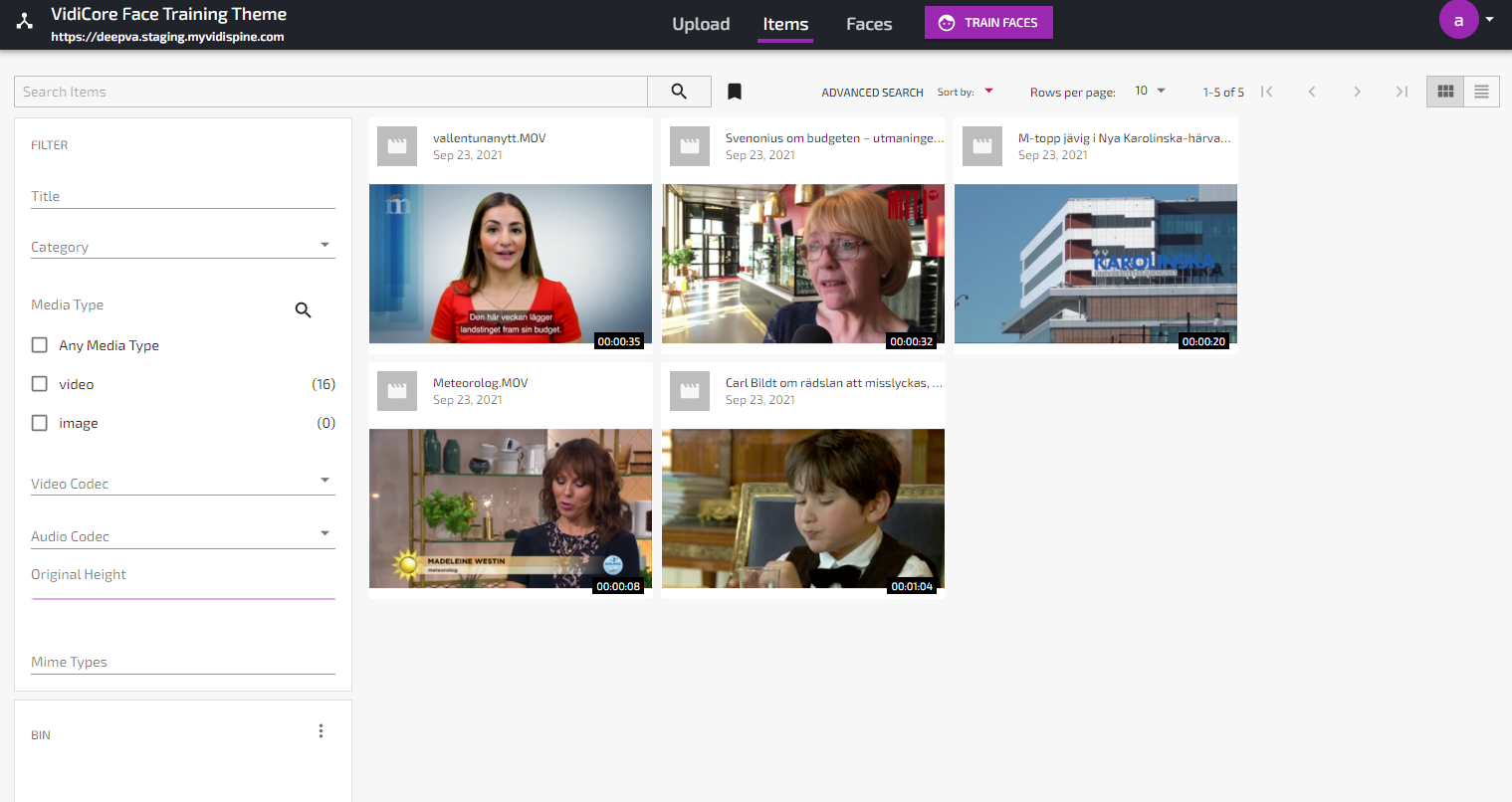
Once you have logged in, you need to populate the system with some video content - preferably content containing people and faces. For this, you can use the Upload function. The upload will create one VidiCore item for each video, with two VidiCore shapes per Item - one shape for the original file and one shape in mp4 lowres format used for playback in the browser. (If you are unfamiliar with the concept of items and shapes it is explained here: Entities in Vidispine [VC 21.3 GEN])
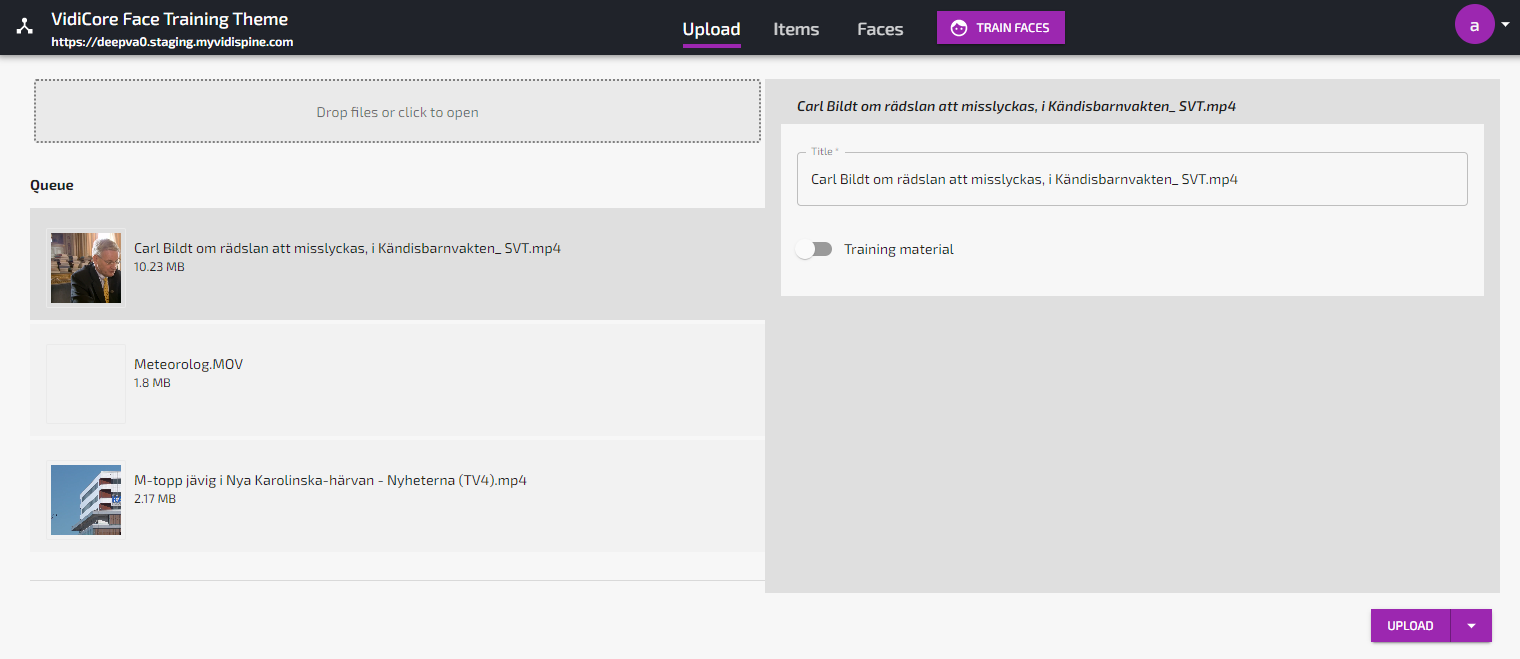
Initialize the Face Database
In order for the DeepVA face model to work, you MUST manually create three faces in the system and TRAIN the face algorithm with these three faces.
If you skip this step, face analysis will not work
-
Go to Upload.
-
Select three portrait picture files with different persons from your computer (must be at least 50x50 pixels).
-
For each image, select “Training Material” and provide a name for the person.
-
When you have marked all three files as Training Material and provided names, click “Upload”.
-
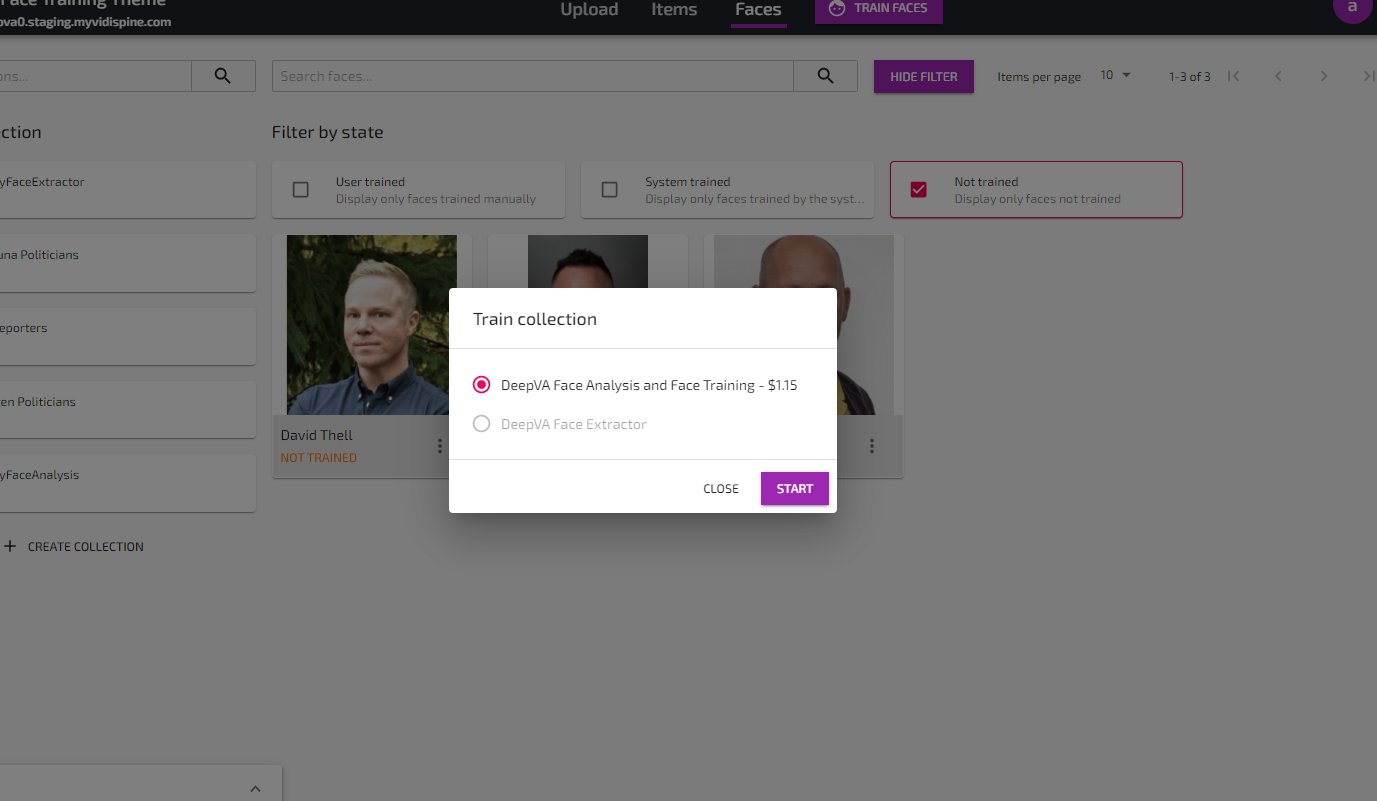
Submit the faces for training with “Train Faces” button.
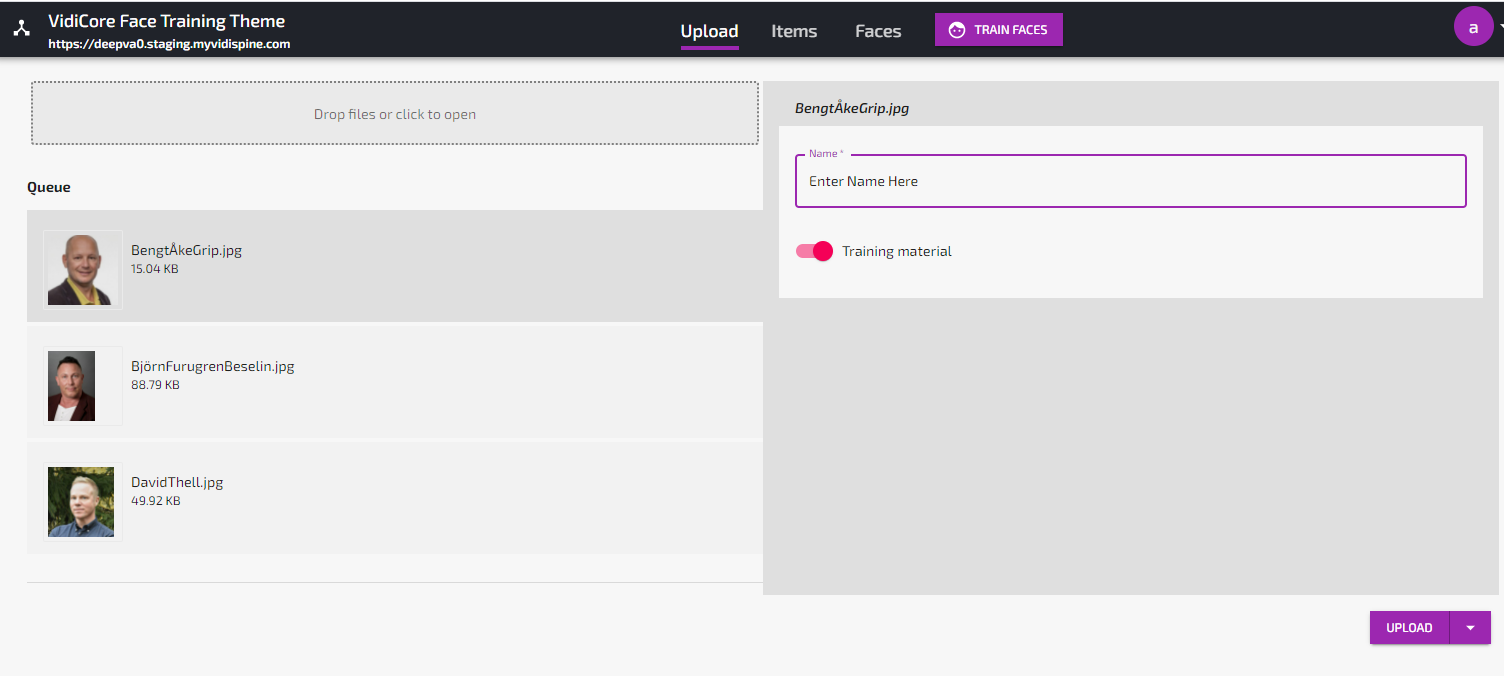
Uploading images to be used for face training
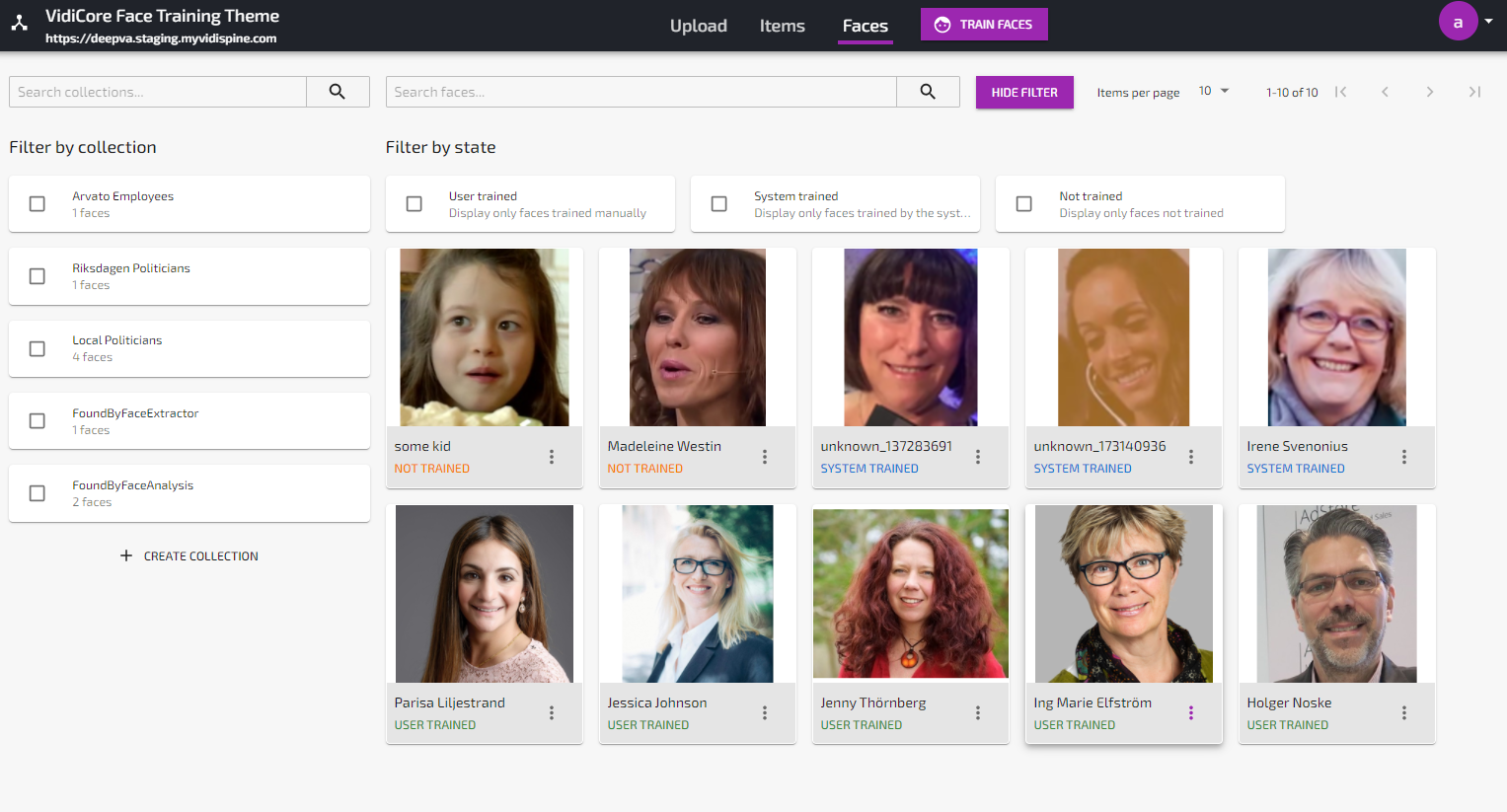
Once uploaded, the faces will be listed in the “Faces”-view with state “Not trained”.
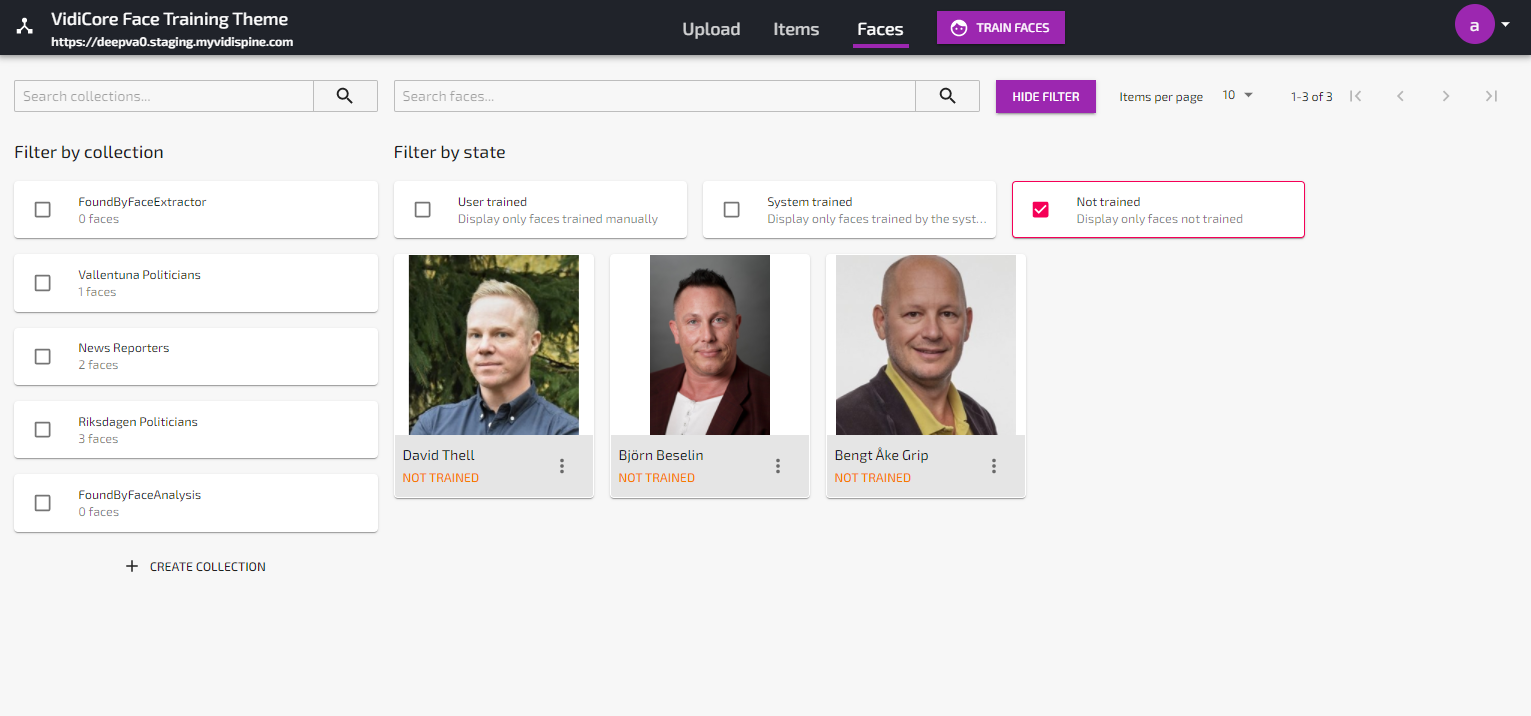
Use the Train Faces button to start a Face Training job.
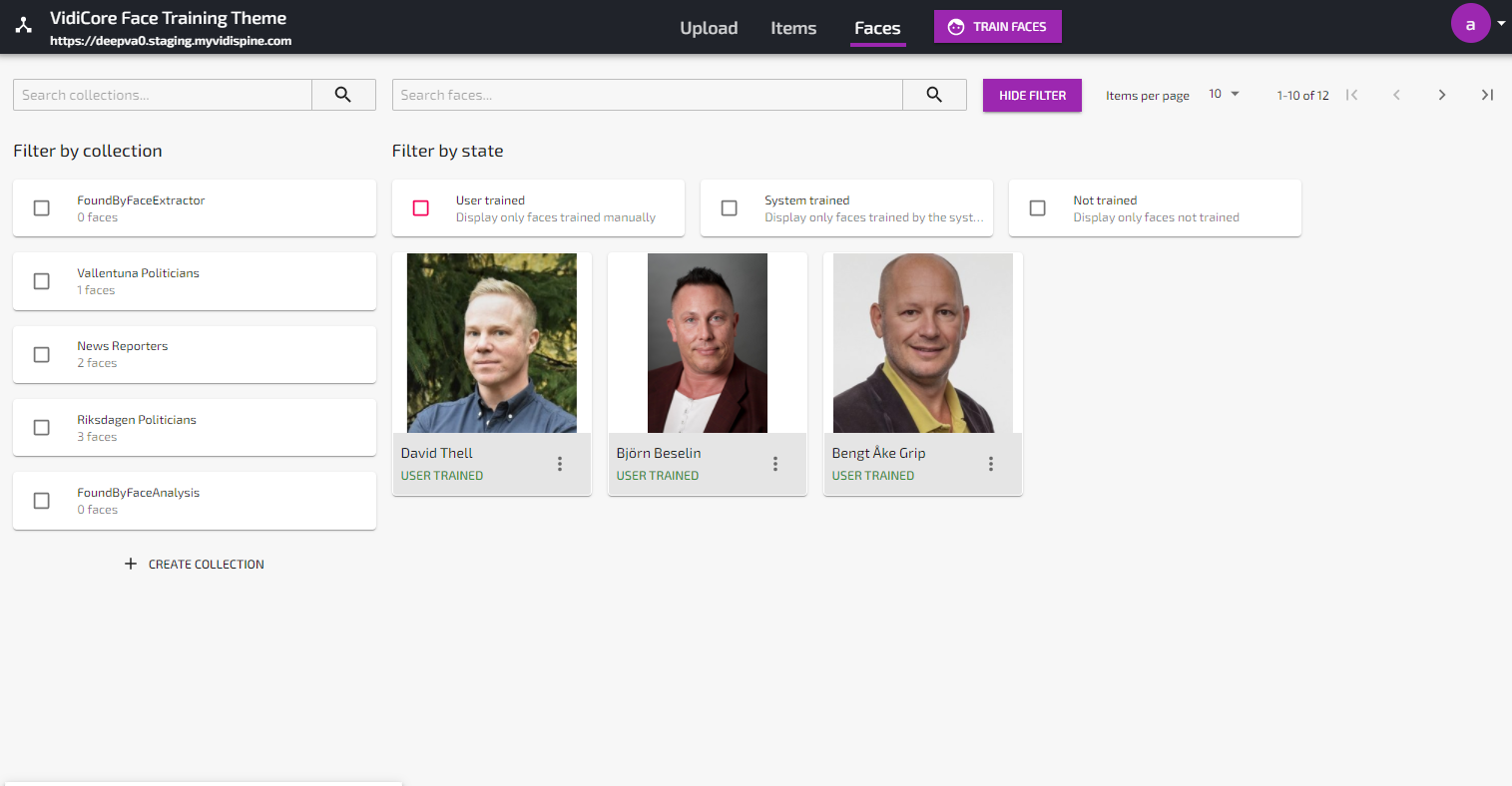
Once the job is done, the faces will get the state “Trained” and the face database has now been successfully initiated.
Analyzing a video and finding faces
Depending on which DeepVA service you select to be used, the output will be different:
-
Select “Face Training and Analysis Powered by DeepVA” in order to identify known faces (using the face database you initialized earlier) as well as find and fingerprint unknown faces.
-
Select “Face and Label Extractor Powered by DeepVA” in order to find faces and automatically create name labels based on information in the lower thirds.
Analyze a video with “Face Training and Analysis Powered by DeepVA”
Analyzing videos to find faces is done from the action menu in the Item Details view:
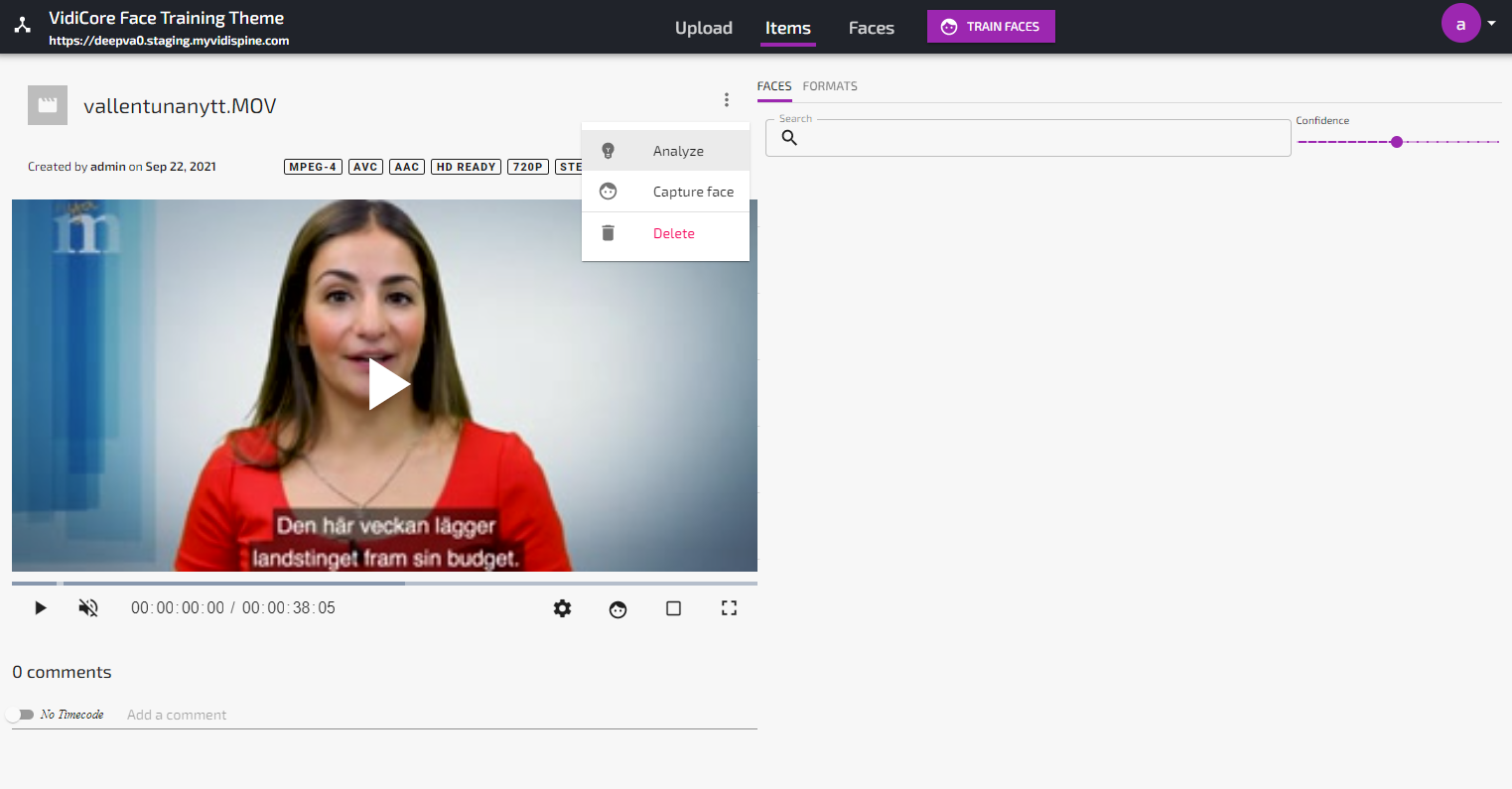
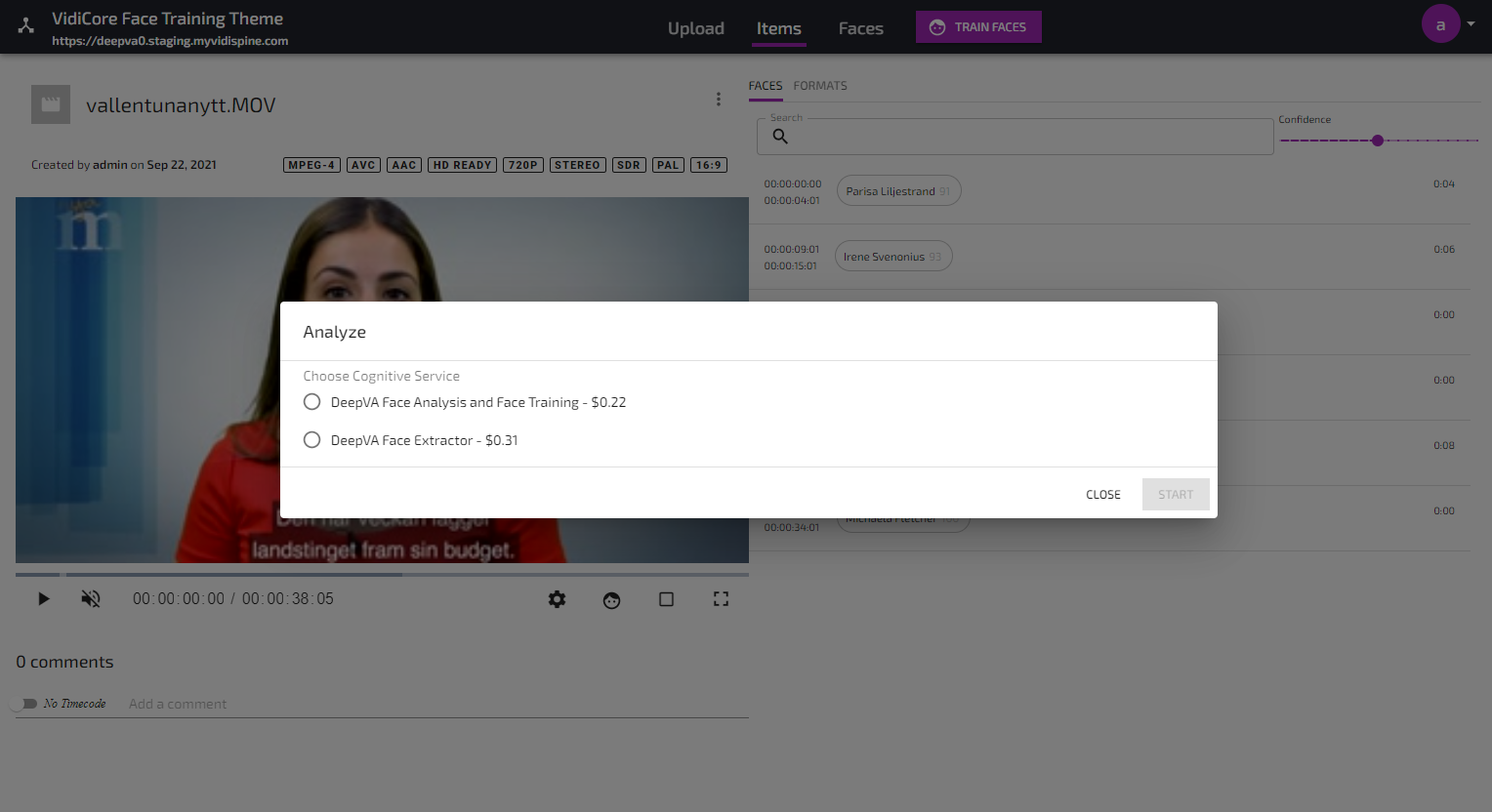
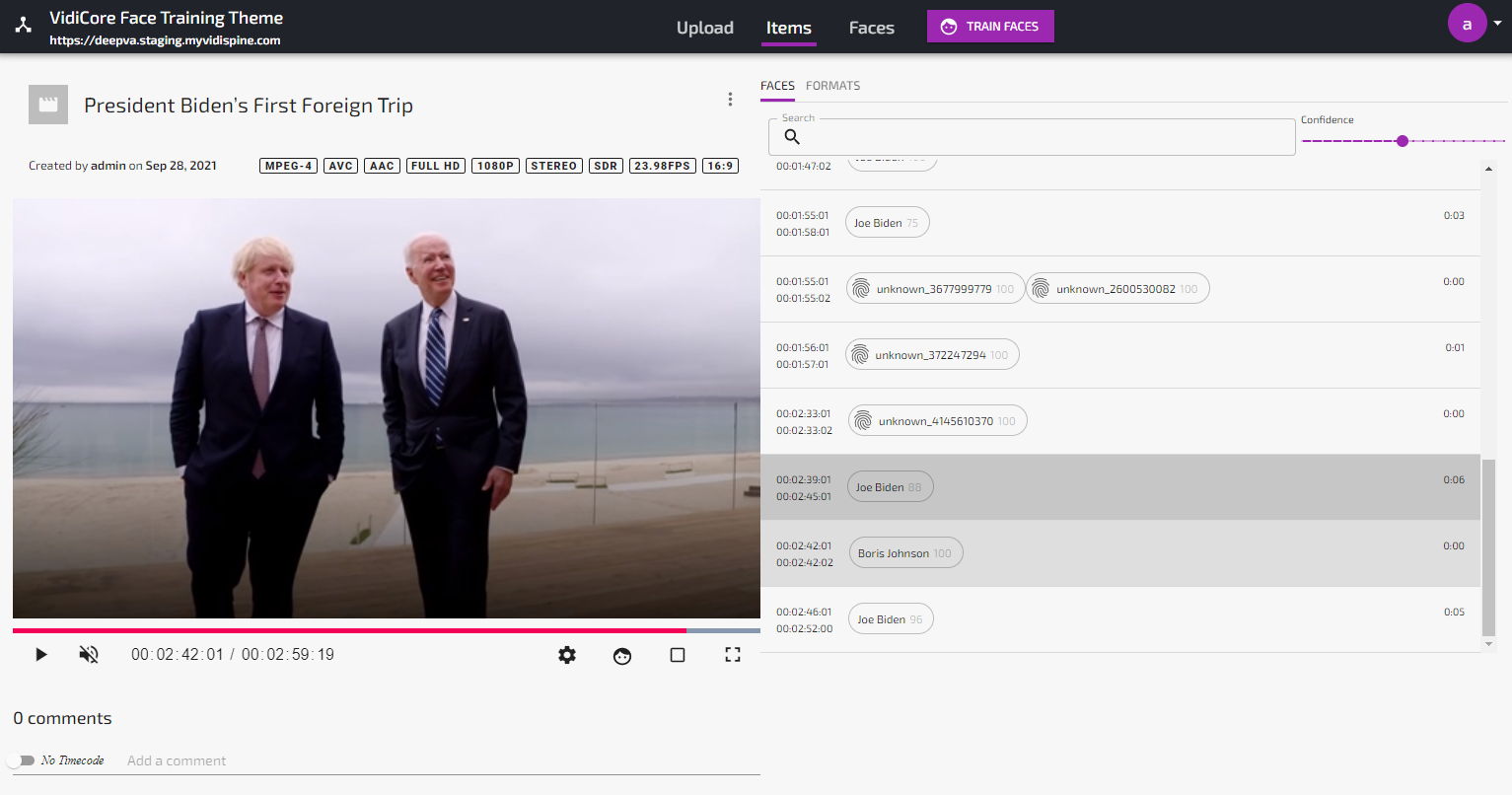
When the analyze job is done, any face found which is unknown to the system will be listed as “Unknown” in the Faces view. If the analyze job found a known face, this will be visualized under the Appearances-tab in the Face details view as well as in the “Faces”-tab in the Item details view:
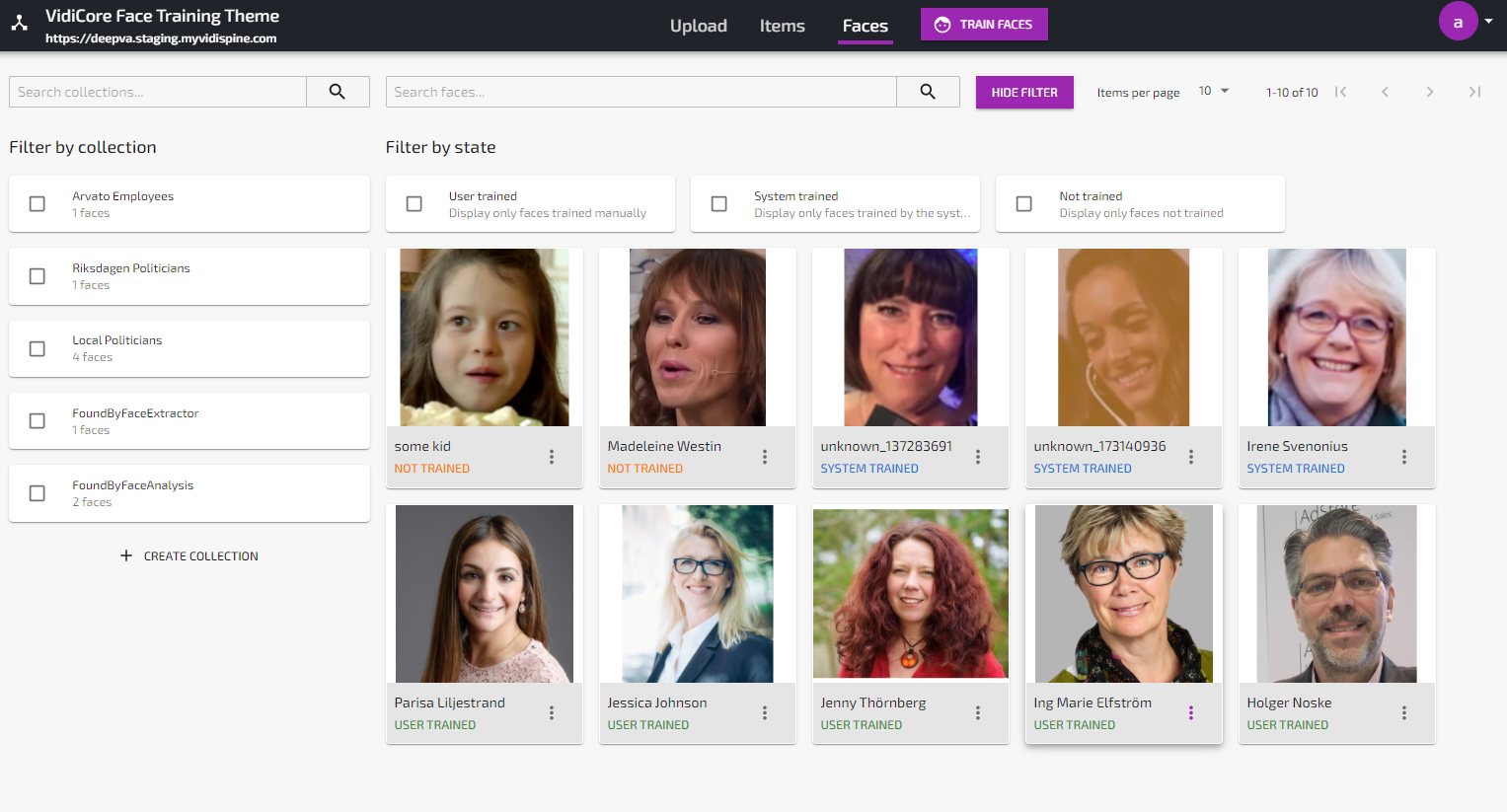
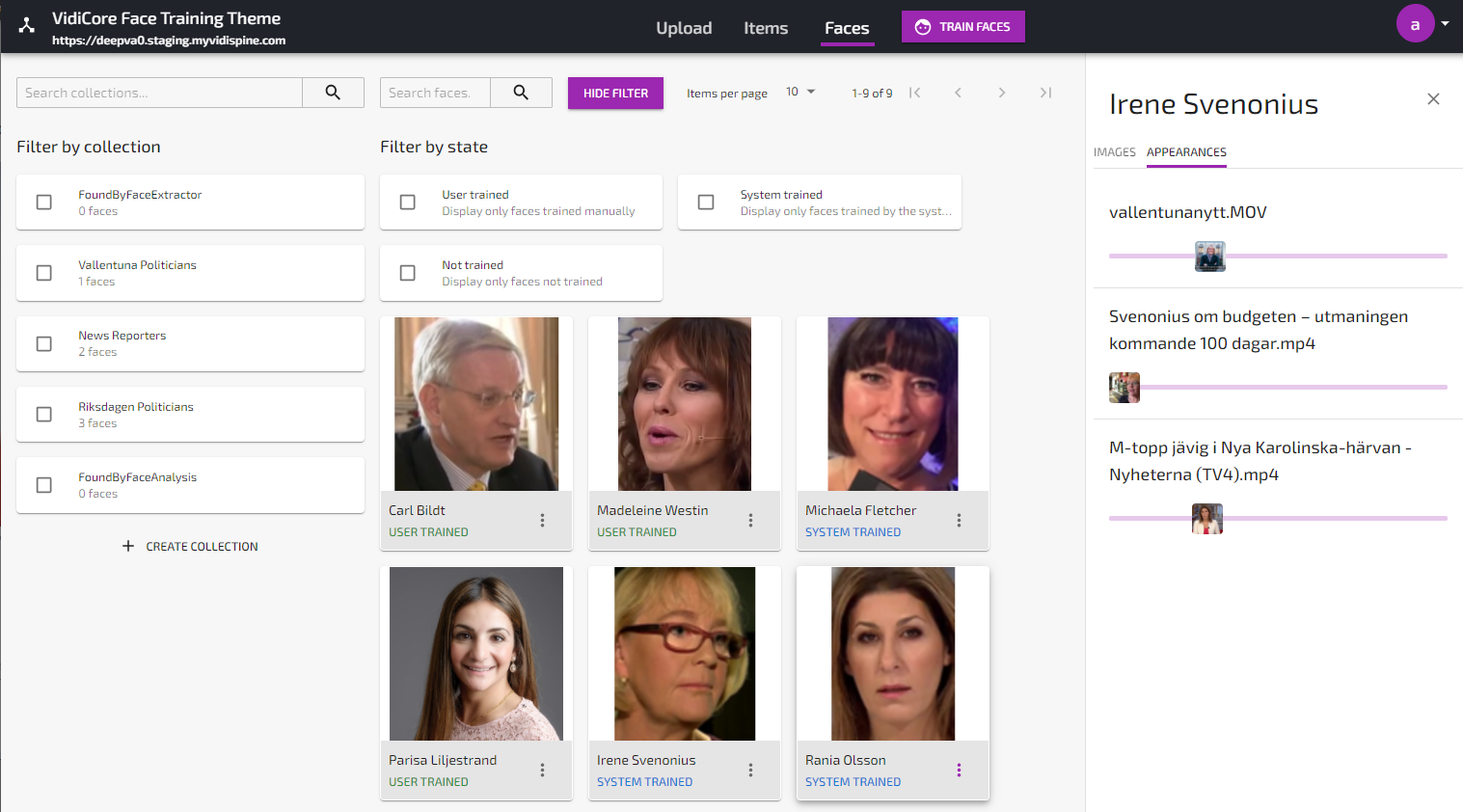
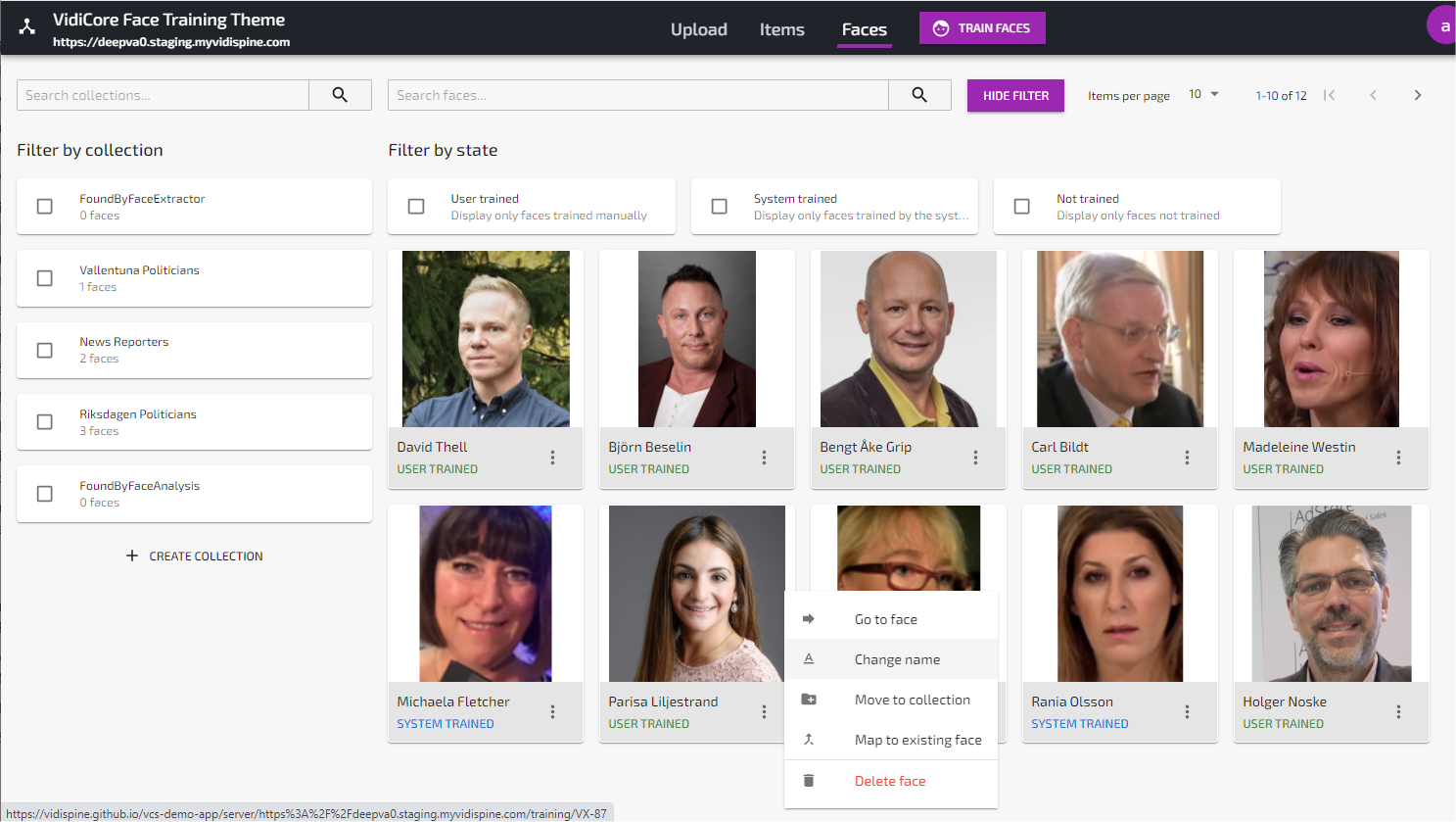
Unknown faces found by the analysis service will be marked as “System Trained” in order to differentiate these faces from the manually trained faces created from uploaded or captured still images. Manually trained faces are marked as “User trained”.
Unknown faces can be promoted to known persons by changing the name from “unknown_xxx” to a proper name using the “Change Name” function in the Faces View or the “I know this person”-function in the item details view.
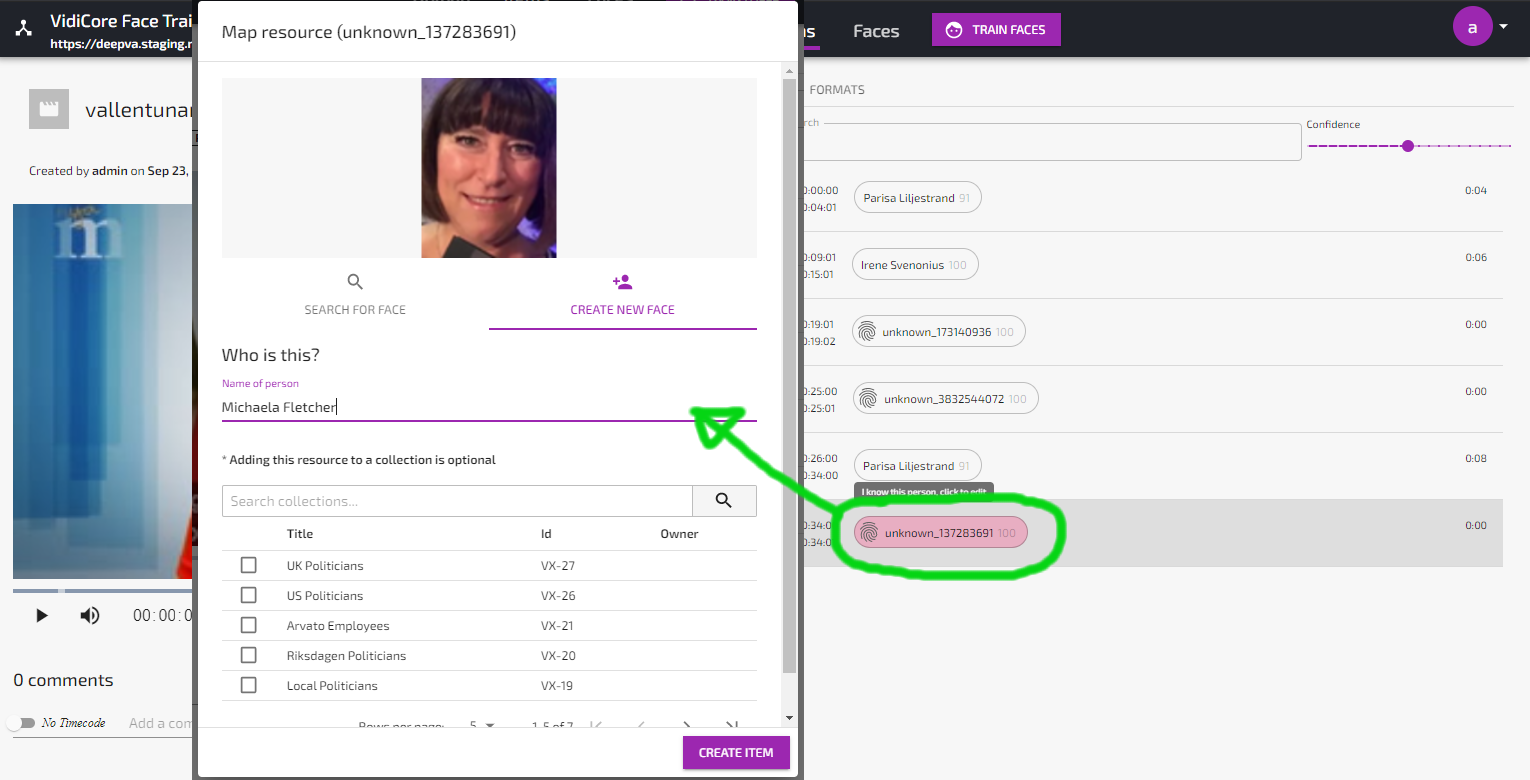
Searching for people in videos
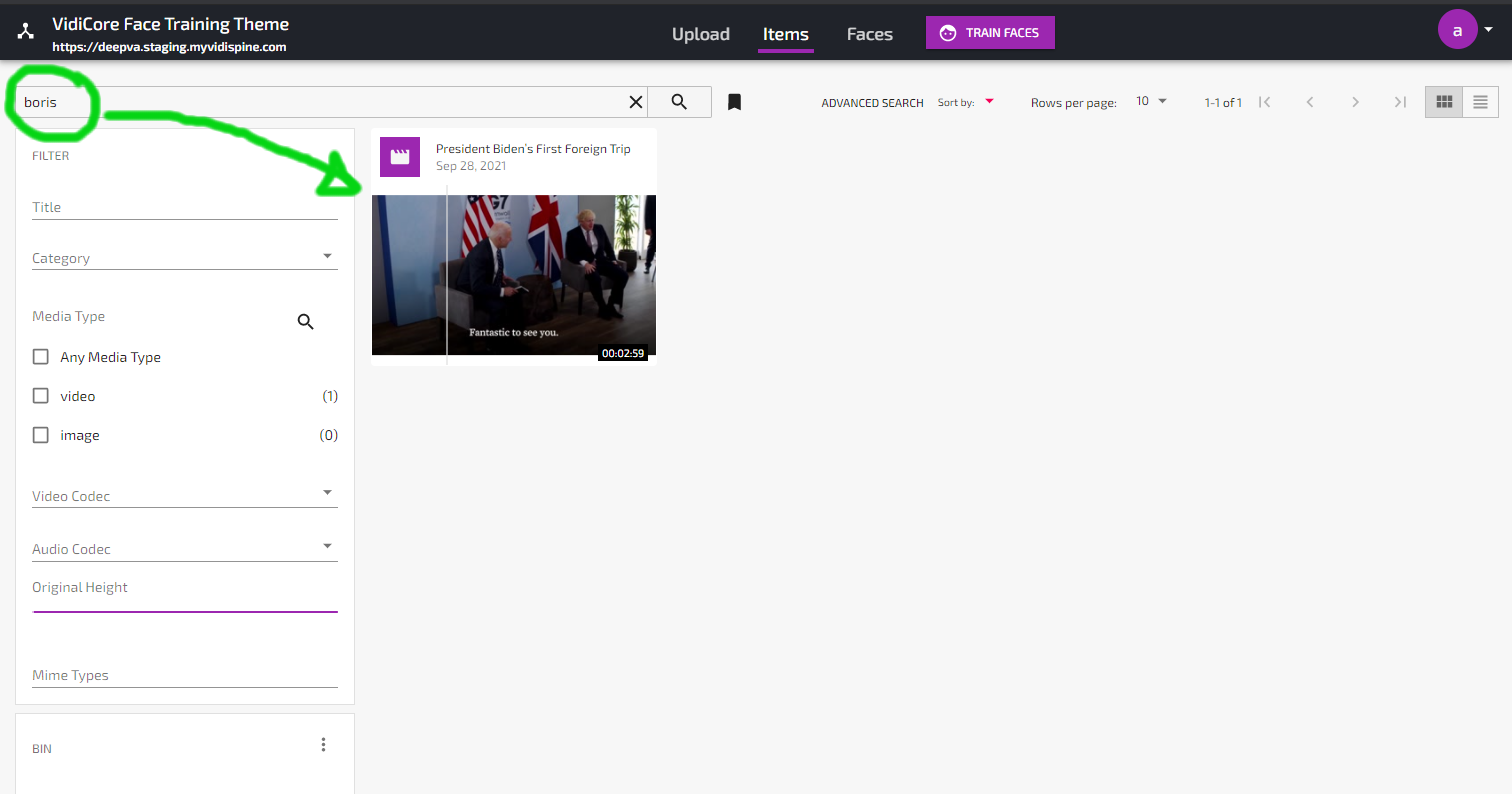
All faces found by the Face Training and Analysis Powered by DeepVA are automatically fingerprinted and stored in the DeepVA data model, and will be used on all subsequent analyzes of any video content, along with all manually uploaded/trained faces. Unknown faces will be labeled “unknown_xxx” until given a name. When given a name, this name will automatically be indexed and can be used in the search function. Clicking a search hit will open the video asset and position the playhead to its first appearance of the face in the video.
Manage and Categorize Faces
All faces found by the “Face Analysis and Training Powered by DeepVA” service will be categorized in the collection named “FoundByFaceAnalysis”.
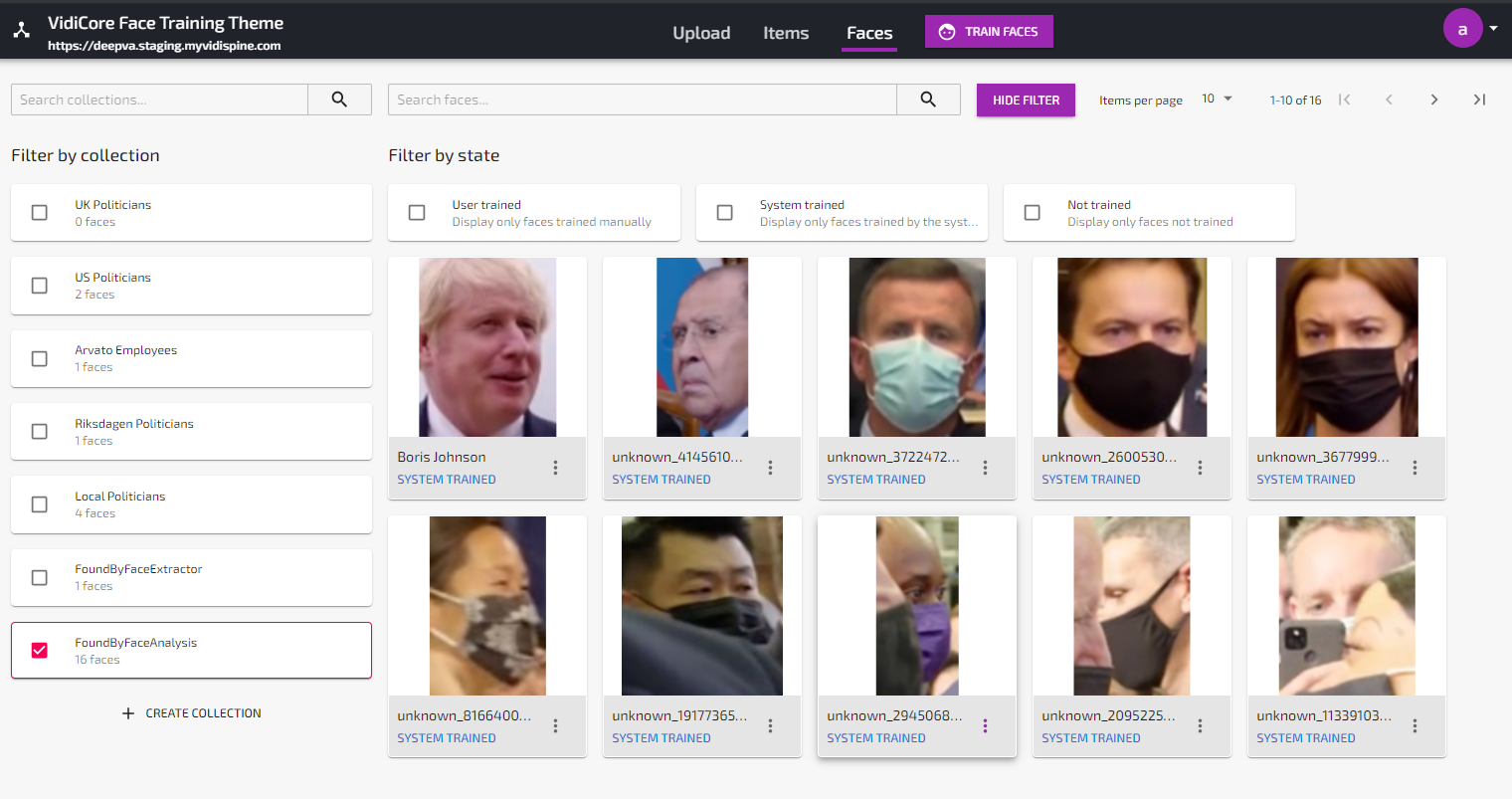
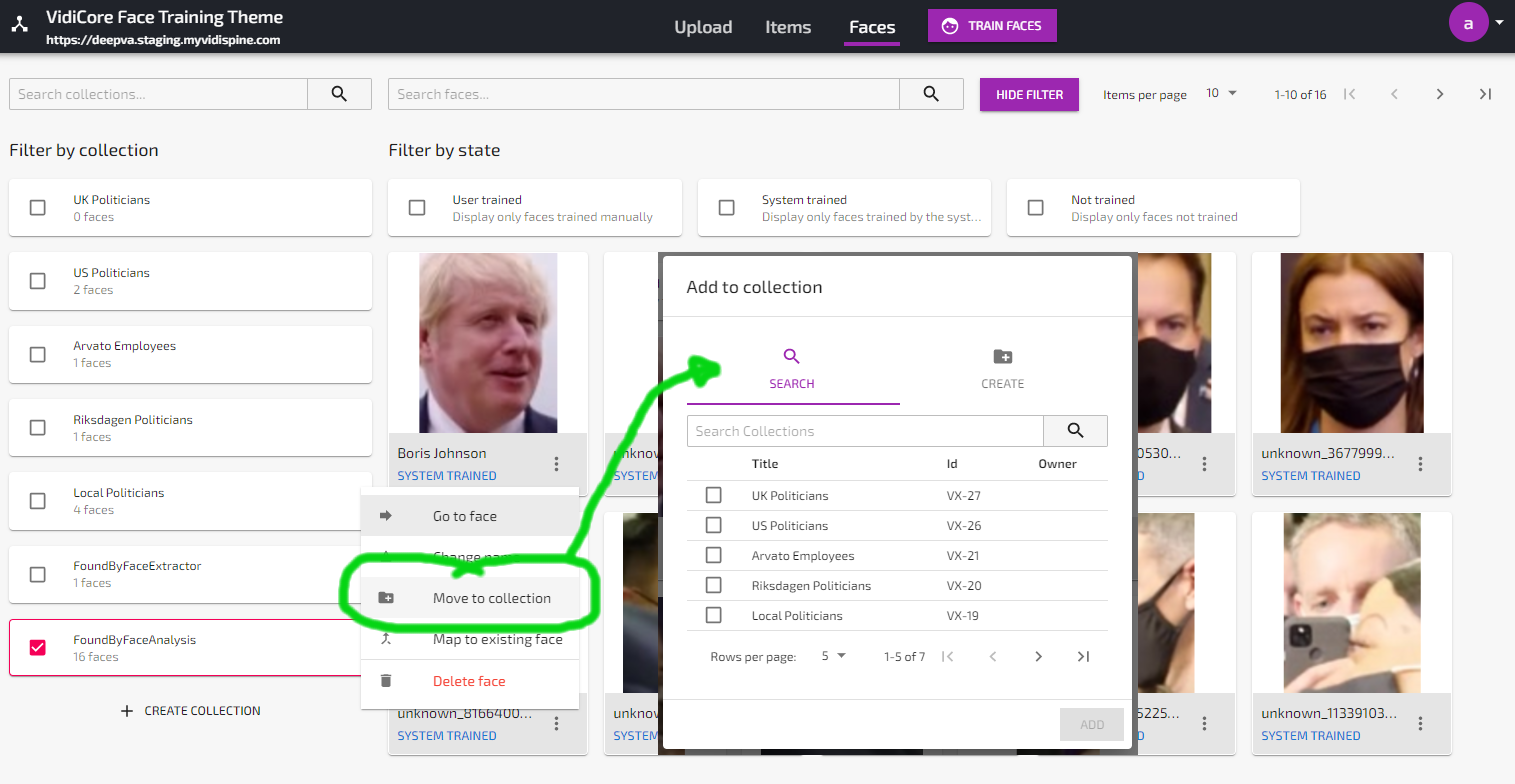
You can use the collection sorting function to catalogue known faces and move them out from the “FoundByFaceAnalysis” collection.
Analyze a Video with “Face and Label Extractor Powered by DeepVA”
Starting an analyze job for this service is done in the same way as the “Face Analysis and Training Powered by DeepVA” service. The difference is the output. The Face and Label Extractor Powered by DeepVA service will look for faces and automatically create name labels based on information in the lower thirds. This is done without creating a system fingerprint and without preserving the timecoded metadata from where the face was found. The output is basically a set of still images of a persons face with a suggested name of the person based on the findings in the lower third.
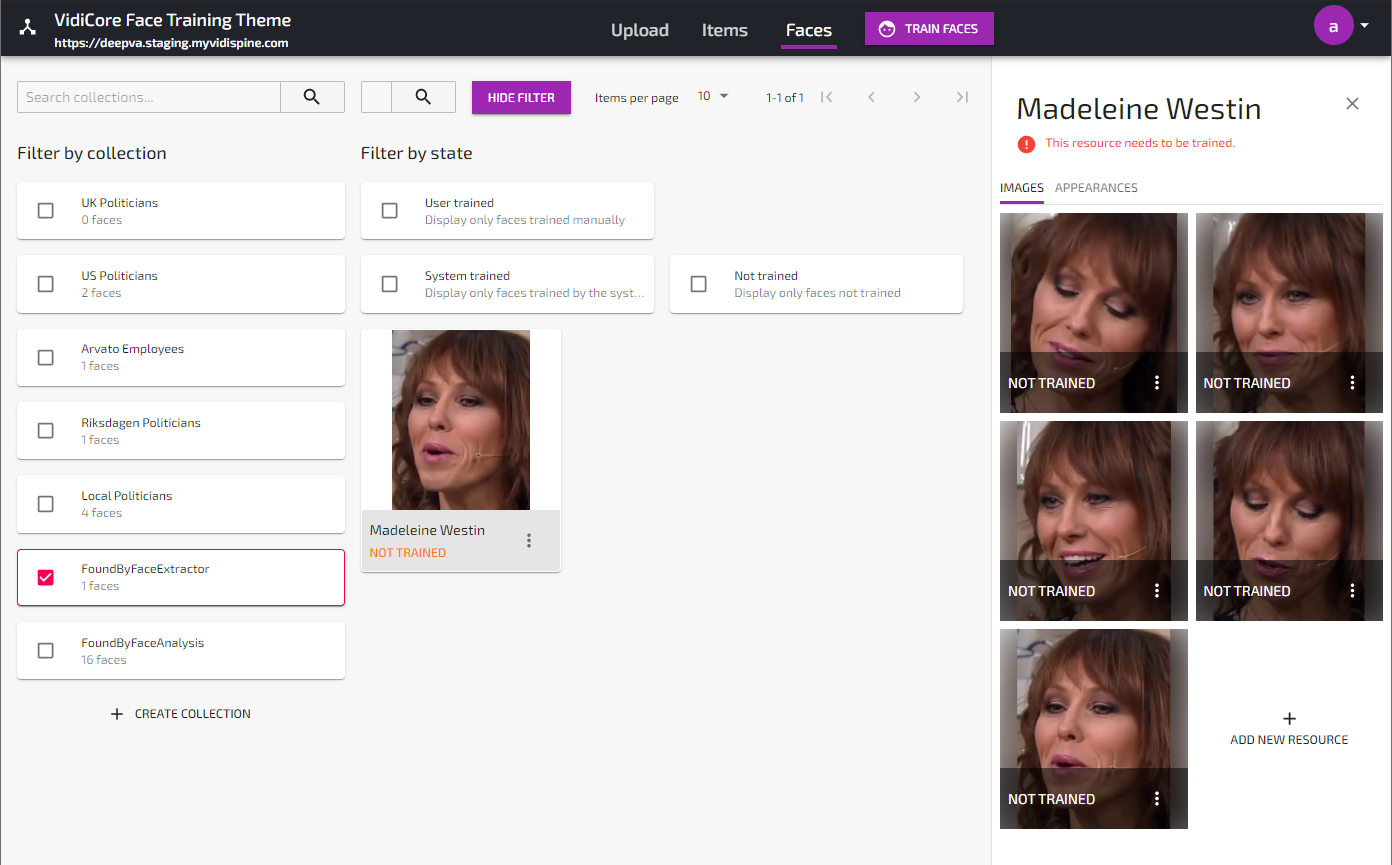
The faces found will be catalogued in the collection “FoundByFaceExtractor”. In order for these faces to be included for Face Training, they must first be moved into any other collection in the system, and then trained using the “Train Faces”-button.
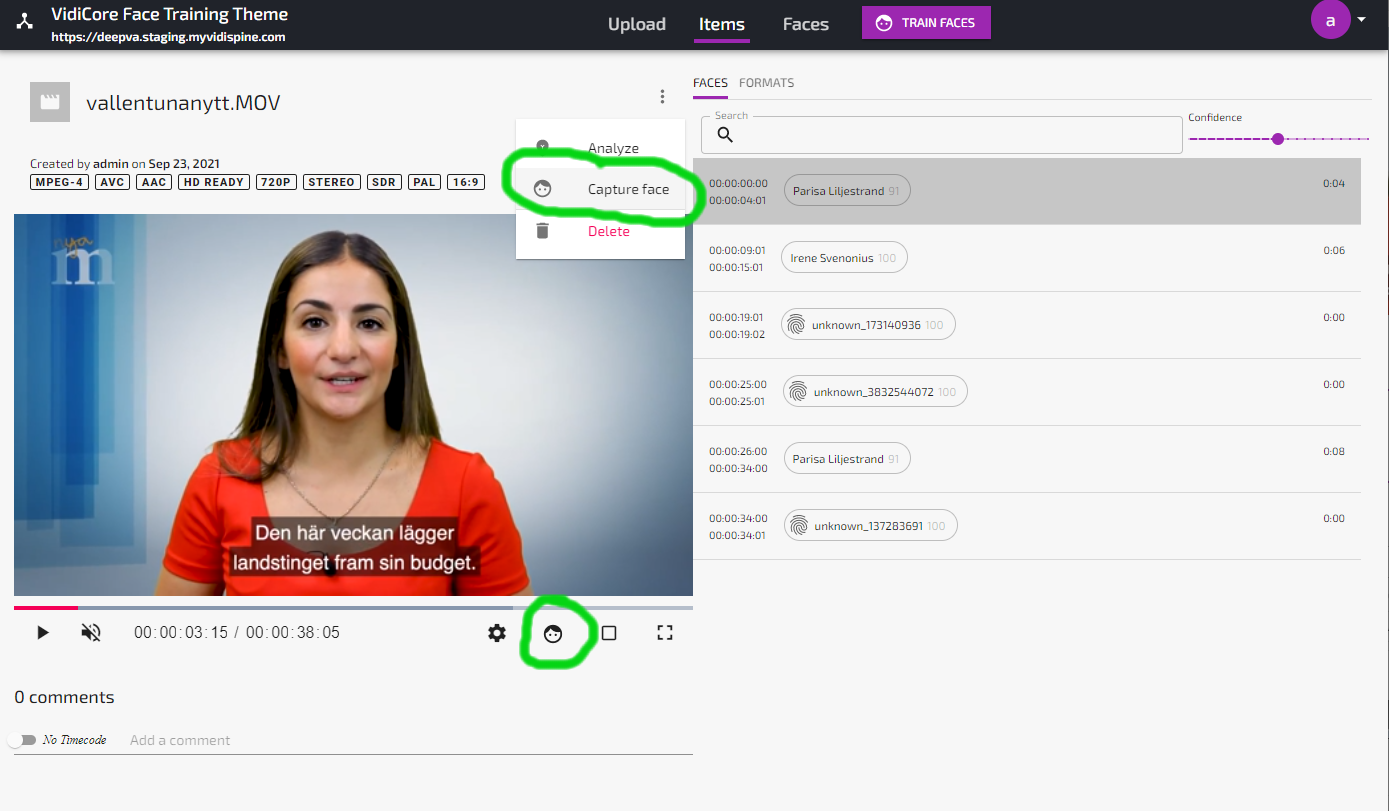
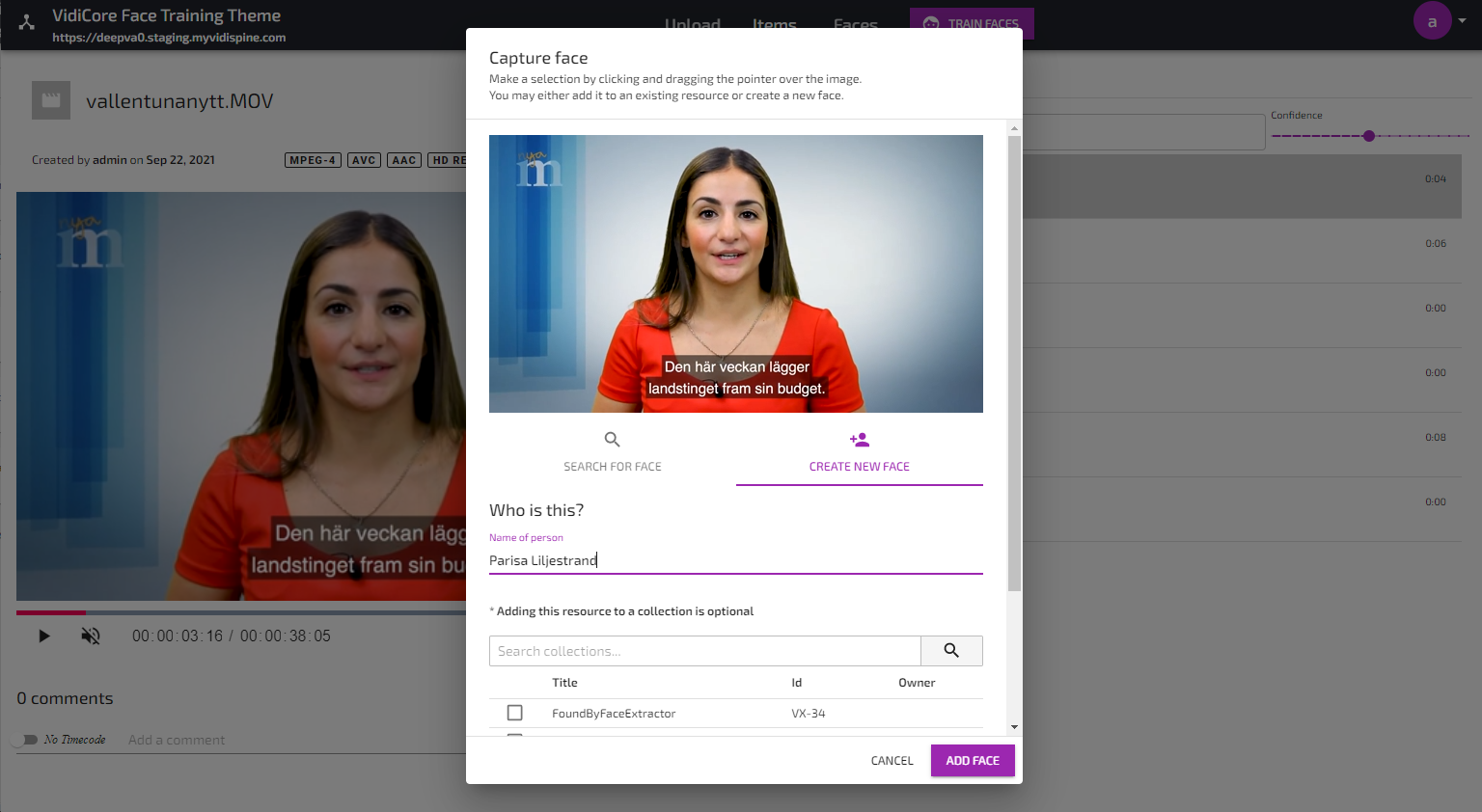
Using the Face Capture Function to Create a New Face Asset
As an alternative to manually uploading image files or using the Face Extractor service, faces can be manually captured from any video in the system. This function will create a new face which must be manually trained in order to be used for subsequent face analysis jobs.